
A large language model for SCIENCE
Meta's Galactica tries to create the ultimate research assistant

Meta recently released a model trained solely on a scientific corpus — Galactica. Surprise, surprise, it got into some controversy. It’s biggest problem: as a model that’s meant to be a scientific assistant, it still hallucinated — came up with “facts” that a simple google search would show weren’t true, and sometimes spit out toxic information.
Flawed as it was, Galactica is a very interesting project, and Meta’s AI division (headed by Yann Le Cunn) obviously had big dreams for it. What was so special about it, then?
Introduction and Motivation
Beyond Developing and releasing Galactica, here’s the paper’s core contributions and ideas:
Instead of other large language models, which rely on an uncurated crawl-based paradigm, GAL’s corpus is high-quality and highly curated.
Because of this high quality corpus, they could train the model for multiple epochs without overfitting, and upstream and downstream performance improves with the use of repeated tokens.
Aside: We saw this mentioned in the Chinchilla paper as possible future work as well!
To allow for more scientific sections like math or algorithms, they create specific tokens that those can be wrapped in, thus teaching the model a distinction between, for example, chemical formulae and explanatory text.
The next section gives some insight into how these different ideas are designed, and how they contribute to the overall product!
Development Details
Dataset
Here’s the dataset breakdown for Galactica. We see it’s trained on 106B tokens, and biggest of their models is 120B parameters.
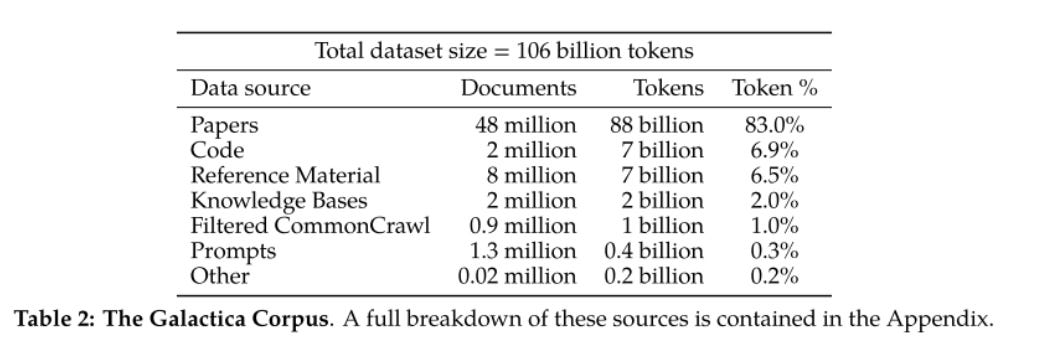
A great question to ask here — does this obey Chinchilla scaling? Not really, but they make up for this by repeating tokens. Their model breaks Chinchilla scaling and succeeds. That’s a pretty big contribution.
Multi-Modality
They enable multi-modality by creating special tokens, in the same vein as <END> or <SEP>. For citations, for example, they wrap them with special reference tokens [START_REF] and [END_REF]. They do similar for numbers, DNA sequences, and mathematics.
Working Memory Token
They create step-by-step reasoning as well, unlocked with a working memory token <work>. The idea behind this token is to allow models to refine their internal representations of data, like humans do.
This is contrasted against the “chain-of-thought” approach. Where CoT requires human effort to find the correct prompt, the working memory token does this automatically. Secondly, humans tend to skip steps with writing down their chain of thought as well — which means the model is trained on data where steps are missing in the writing.
Finally, the model offloads tasks like programming or arithmetic to its toolbox, similar to what Google’s LaMDA was doing. This highlights the model’s strengths and hides its weaknesses.
Evaluation
Galactica outperforms GPT-3 by 68.2% versus 49% on technical knowledge probes such as LaTeX equations.

Galactica outperforms Chinchilla on mathematical MMLU by 41.3% to 35.7% and PaLM 540B on MATH with 20.4% vs 8,8%

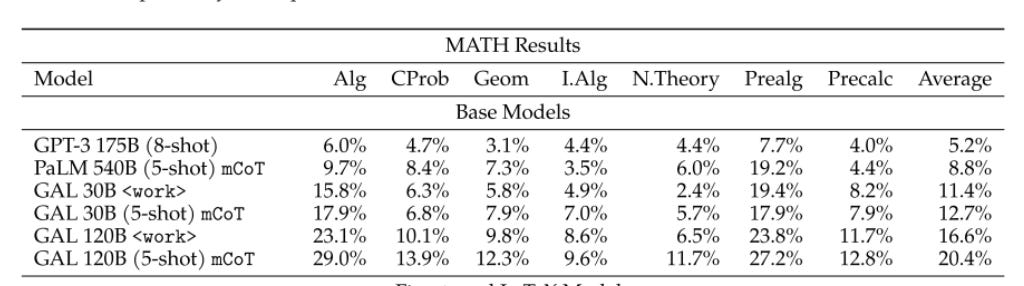
On downstream tasks like PubMEDQA and MedMCQA, it creates SOTA results of 77.6% and 52.9%.
Despite not being trained on a general corpus, GAL outperforms BLOOM and OPT-175B on BIG-Bench.



Limitations and Future Work
Despite being trained specifically to master specific scientific domains, GAL120B does not outperform Chinchilla, which is a much smaller model.

The paper mentions the process of “offloading” a problem the model can’t solve to a program — the model doesn’t currently do such offloading, but would benefit from it in future work.
Currently, the Galactica corpus is focused on graduate knowledge, from research papers. How to balance research with general high school knowledge remains a future task.
Some mild evidence exists in the paper to suggest that the increased epochs make the model worse at out-of-domain tasks. Future work could collect evidence for this.

Incredibly, the paper itself has a limitations and future work section!

It is increasingly rare for researchers to share the flaws in their paper and what they’re looking to build in the future in such an explicit way, so definitely check this out!