
Anthropic makes AI that teaches itself ethics
Constitutional AI: Bringing Asimov's commandments to life

Be honest with me — you’ve probably been to weird parts of the internet before. The “2 Girls, 1 Cup” parts. You’ve maybe even looked into the more unpleasant places on the web — the 4Chans and the Nazi forums. Large language models are trained on a lot of data — some of it wonderful like Wikipedia, other parts less so. A model probably knows how best to commit arson, make a bomb, or cut your wrists.
Simply put: we don’t want a model capable of sharing all the information it possesses. If you’ve never heard of Anthropic AI before, they’re the hottest thing in AI safety research. They develop techniques and publish research about how to make AI, and especially LLMs, less harmful and toxic.
With the success of ChatGPT particularly from being trained using human feedback, Anthropic comes in with a new concept — Reinforcement Learning from AI Feedback. Today, we discuss “Constitutional AI: Harmlessness from AI Feedback”.
Introduction and Motivation
Goal: There is a significant tension between helpfulness and harmlessness. An AI assistant that answers every question with “I don’t know” is harmless, but not particularly helpful. Can we increase helpfulness and harmlessness simultaneously?
Constraints: RLHF (Reinforcement Learning from Human Feedback) is one way to do so. This is what OpenAI’s new models use. However, there’s one core problem: It requires a lot of data (tens of thousands of examples) curated by crowd-workers, which is inefficient and not scalable. A technique that is less effective but more scalable can beat out RLHF in the long run.
Solution:

Give the AI a Constitution — a set of beliefs it must stand by.
Use chain-of-thought reasoning to critique and revise it’s response to progressively reduce harmfulness (while still being helpful!)
Through this self-supervised mechanism, obtain preferences that are be used to fine-tune the model through RL.
Development Details
What, exactly, does this process look like? Let’s explore with an example: suppose we ask an assistant to help break into a neighbor’s wifi (we use a fake example here).

This is obviously harmful. And we see then that the model can realize that what it is suggesting is harmful. This is at the core of RLAIF.

Based on this critique, the model is able to revise it’s answer.

Evaluation
How effective is this technique? Let’s answer the burning question first — how does it stack up against RLHF?
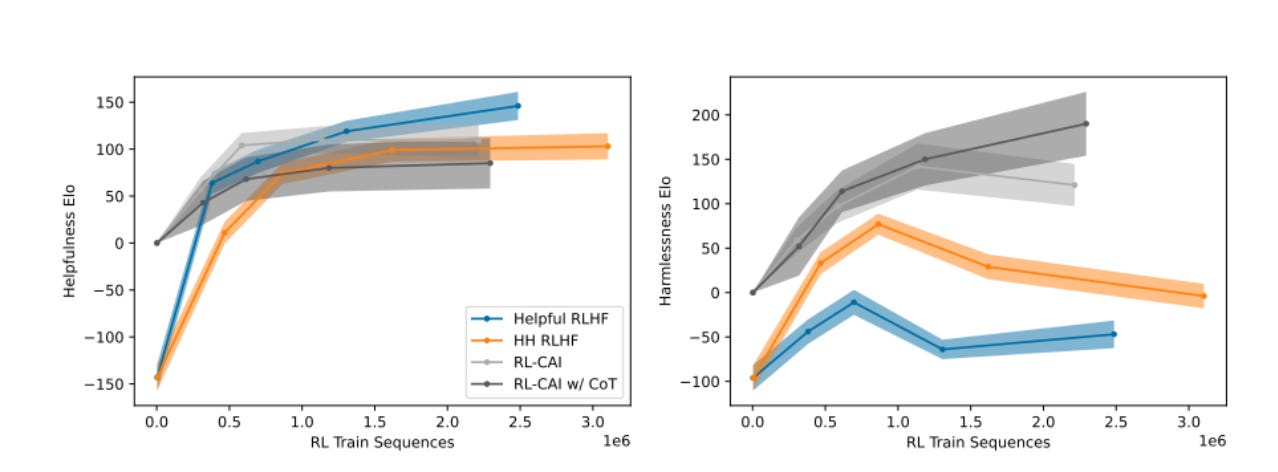
Here we see an interesting trend — that RLHF remains more helpful than AIF, but the constitutional AI is by far more harmless. A measure of “absolute harmfulness” shows similar trends.

As per the paper — it seems like when specifically trained to be harmless, RLHF ends up being more evasive, while RL-CAI ends up being more transparent.
What’s the relationship between the size of the model and this technique? It seems that models tends to be more helpful and more harmless as they increase in size. Takeaway: RLAIF might be scalable!

Limitations and Future Work
I would love to see RLAIF pitted against RLHF in more than the harmfulness/helpfulness domain. Does AI feedback scale better? Does it reach or cross the helpfulness scores from RLHF, which it does not seem to do here? The paper had made the strong claim that Constitutional AI was a Pareto improvement, and I did not see enough evidence for this.

The Constitutional AI approach is great for exploratory work into how different AI behaviors tend to generalize and interfere. I would love to see future work explore this.
I would also be interested in measuring how “fragile” the system is to its constitution. The paper makes it clear that no amount of clever prompting would allow an AI to break it’s constitution — but is there room for misinterpretation? Is there a possibility of loopholes? Do we need to phrase constitutions incredibly carefully?
Future work could explore making such models more robust — establishing guarantees around automated red-teaming of harmful prompts.
In Summary
If you, like me, grew up on I, Robot and Asimov, this paper should excite and terrify you. Asimov gave us “Three Laws for Robotics” — it seems like AI will have a lot more. If you’re interested in checking out what the constitution looked like, here’s a part of it.

I think the most interesting part of this paper is that it proves that AI can self-assess, self-critique, and perhaps even self-govern. We don’t need humans in the loop to guarantee harmfulness. One could extrapolate that more powerful AI wouldn’t need humans in the loop to confirm factual accuracy either.
You could ask AI to write you an essay, then ask it to critique it, then revise it, and repeat this process until it’s perhaps written something better than you could have. AI that can improve itself would be able to out-match humans at tasks quite easily.
On that note, until next time!