
Composing models together makes them powerful
A look into what chaining models together looks like

If you’ve been on Twitter or the LLM builder community, you’ve probably interacted with LangChain AI.

The core idea behind the project — “using LLMs in isolation is often not enough to create a truly powerful app - the real power comes when you can combine them with other sources of computation or knowledge”. This means combining LLMs with tools like calculators (like LaMDA) or even combining models together.
It is this model composability that lives at the heart of “ViperGPT: Visual Inference Via Python Execution for Reasoning”.
Introduction and Motivation
Goal: Query an image with a question the way we do with LLMs or Google. Move beyond the image domain’s ML problems of classification, generation or segmentation.

Constraint: Training an end-to-end visual model that can answer questions would require a very big model and a lot of data — which is often not available. Training like this is hard.
Core Insight:
Visual models are good at answering a small fixed subset of questions (Does X exist in the image? How many? etc)
Language / Code models are good at decomposing a high-level query into steps that can use visual-model-specific questions.
If we compose them together, we can leverage their collective strength.
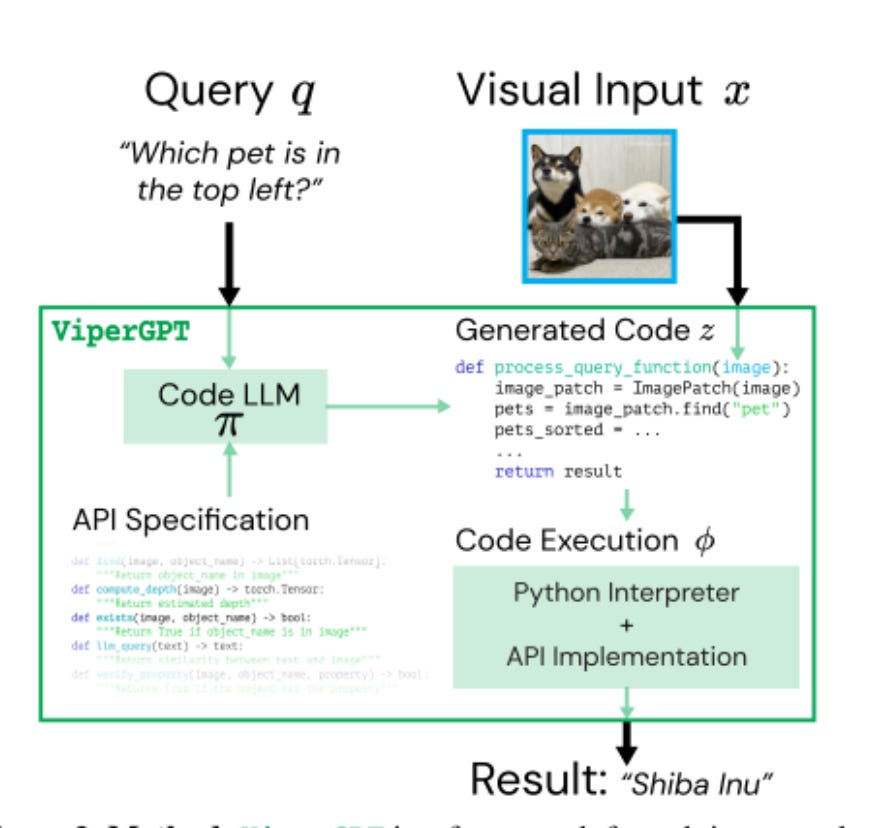
This technique would allow the model to (hypothetically) excel in four domains:
visual grounding
compositional image question answering
external knowledge-dependent image question answering
video causal and temporal reasoning
Evaluation
To test our hypothesis about what this model could perform well at, let’s look at some data!
Visual grounding is “the task of identifying the bounding box in an image that corresponds best to a given natural language query. Visual grounding tasks evaluate reasoning about spatial relationships and visual attributes.” Here’s an example of what that means:

On the RefCOCO visual grounding dataset, Viper excels in the zero-shot domain.

At compositional question-answering, the model performs well in both the temporal and the causal domain.
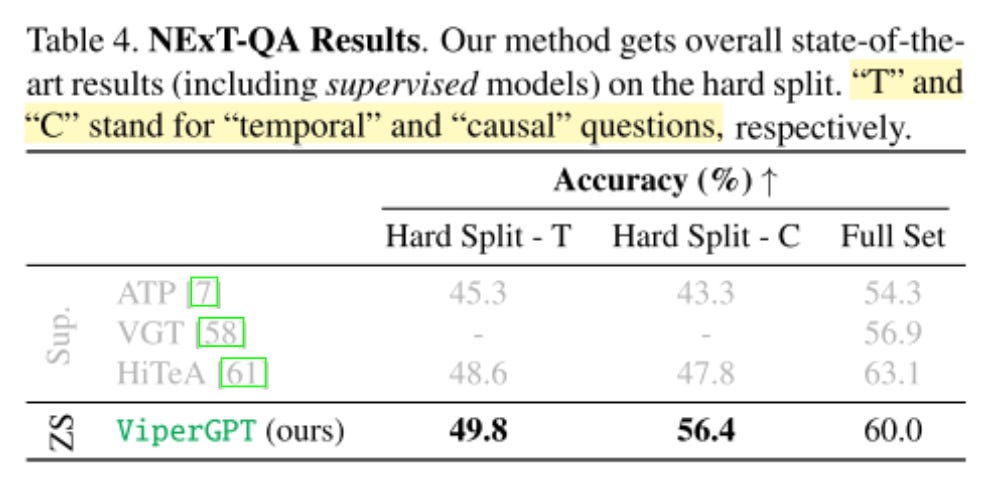
Here’s a great example of temporal reasoning an end-to-end model probably could not achieve

Since we have the code interface, we can also inject external information! This is a very interesting addition to the realm of image QnA.

Limitations and Future Work
If you look at the evaluations above, you would see that the method is surprised by supervised learning models. First, I wish the paper had spent more time justifying why this was the case. Second, this is interesting but not unsurprising. Whenever possible, supervised learning will be more compute and time-optimal — you learn faster and better with labels. So, if these supervised models exist and perform well, why does ViperGPT have to exist? I would have liked to see a comparison of the advantages of using self-supervised models.
Composing models together can be very error-prone. This is for a few reasons: lacking context about other things in the chain through any mechanisms beyond their prompt, language models can resort to hallucinating. They don’t have strong enough grounding mechanisms. A singular wrong answer from he image model can veer the language model off on the wrong path. I would like to see the benefits of few-shot learning and feedback loops evaluated in the next paper. I would also be interested to see such work use shared embeddings to unify the visual and language model.
In Summary
I have a complicated relationship with papers like this — which feel like they could’ve been created at a weekend hackathon. This isn’t meant to be shade — the idea is simple and it works. They did it first. Simple or not, they were on to something.
The core insight: various domains can be easily composed together; this is probably where models are headed. Code is the best interface for structured reasoning, since execution is an easy mechanism for sanity checking reasoning. But integrating all these domains together is going to be more complex than simply piping input to other.
I really like papers like this: you could string together two API calls on huggingface and get a rudimentary viper working. Simple ideas are often the most powerful.
Until next time!