
Cramming: Training a Language Model on a Single GPU in One Day
What's all the noise about?

We interrupt our Summarizing NeurIPS Outstanding Papers series to bring you breakdown of a small paper generating a lot of noise on AI Twitter.
Introduction and Motivation
With massive scaling in neural model parameters and training, deep learning research is becoming increasingly centralized. How much can a modest researcher with a good GPU achieve with one day of training?
Goal: Benchmark conceptual progress of deep learning research.
Constraints:
Transformer-based language model
No pre-training in any part of the pipeline
Training data can be cleverly chosen using sampling methods
Downloading and pre-processing of raw data is not part of the compute budget
Core Problem: Scaling laws create a strong barrier to scaling down. Per-token efficiency of training depends strongly on model size. That is, smaller models learn less efficiently.
Solution: Smaller model = throughput gains. Use models that speed up gradient computation, keeping parameter count constant.
What Worked, What Didn’t
The following amendments upon the vanilla architecture provided improvements:
Disabling all linear layer biases in the feedforward block, removing the nonlinear head and the the decoder bias.
Scaled sinusoidal positional embeddings (over unscaled sinusoidal embeddings)
Pre-normalization with layer norms (vs post layer norms)
Gradient clipping in Adam optimizer.
Re-scaling learning rate schedule to tie to budget and the learning rate decays as the budget reduces to zero.
Aggressive batch size schedule (to counter the necessarily of a smaller-than-optimal batch size due to one GPU)
Remove dropout during pre-training (no fear of over-fitting)
Swapping data sources and additional processing to optimize data — removing hard-to-compress data like HTML code.
Sorting tokenized sequencing by prevalence (likely sequences occur first)
Increasing final batch size at the end of training (reduce fluctuations to data distribution)
Rotary embeddings provided small benefits (but decreases speed, was ultimately removed)
The following additions showed no benefits or negative effects upon the vanilla transformers:
Varying the transformer size and type has minimal impact on final loss
Offloading data and compute to the CPU [2]
Unsupervised tokenizers of raw data like SentencePiece [3]
Small vocabulary resulted in worse performance, while larger vocabularies didn’t necessarily improve performance.
Replacing: softmax layer, activation function, attention head, layer normalization, loss function, optimizers
Reducing the number of attention heads
Decoupling the input and output embeddings, or factorizing the input embeddings
Masking at larger rates than 15% during training
As can be inferred from the above lists, the paper is thorough! While our summary captures all the big trade-offs, in-depth discussion on any of these can be found in the paper.
Evaluation
The “crammed” model is evaluated against BERT on a variety of training sets:
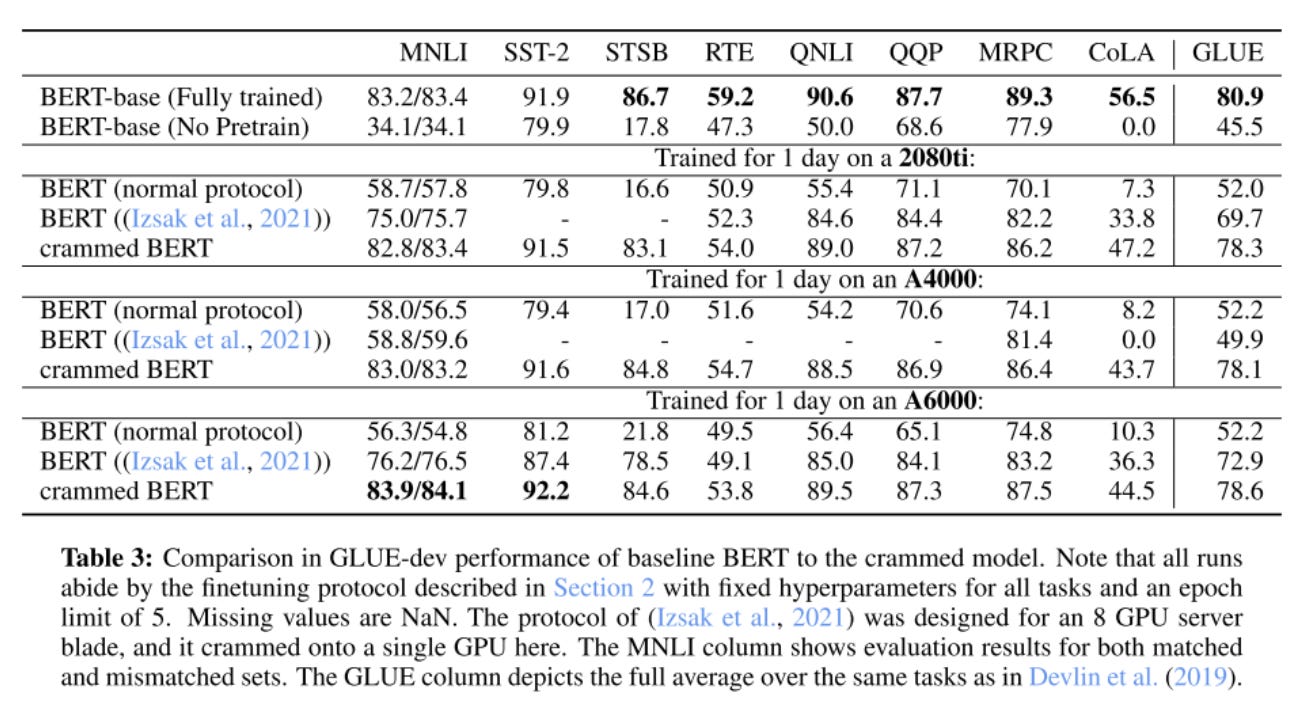
The performance of the original BERT being much lower is a result of squeezing it onto one GPU, when it was designed for a full 8 GPU server blade.
Generally, the crammed model performs well, except on CoLA benchmark. This might be because:
CoLA is sensitive to hyperparameters during fine-tuning
The crammed model just needs more data before it develops linguistic ability.
Limitations and Future Work
The authors claim they would like to further loosen the constraints they placed on themselves to continue exploration. Maybe the ideal architecture isn’t a transformer, even!
Beyond that, this paper is exceptionally well-written, detailed, and honest. It is also a good read for those trying to catch up with the transformer-based developments from the last few years. I’d highly recommend reading it end-to-end!
References
[1] Paper link: https://arxiv.org/abs/2212.14034
[2] https://arxiv.org/abs/2101.06840