
Discovering a better optimization algorithm with evolution
Google's Lion optimizer matches or outperforms Adam across the board

Optimization algorithms live at the core of modern machine learning. Since the discovery of Stochastic Gradient Descent in the 1950s, we’ve come a long way — AdaGrad, RMSProp, and the current reigning champion: Adam. Here’s an example of optimization algos going up against each other:

Adam was first introduced in 2014. It seems like we’ve hit a bit of a local minima (hah) when it comes to these algorithms. That is, until one week ago. Today we’re looking at “Symbolic Discovery of Optimization Algorithms” by Google.
Introduction and Motivation
Goal: By framing finding algorithms as finding combinations of functions, we can cast finding optimal algorithms as a search space problem. Anything you can cast as a search space can be navigated and optimas can be found.
Constraints: This is not a new discovery — people have been changing optimization problems into search space problems for decades. The problem remains — most optimization algorithms create a sparse and infinite search space, which is intractably large. That is to say, you randomly generated programs from this space, the probability you would find something valuable is infinitesimally low.
This paper is divided into two parts:
Techniques they used to restraint and efficiently navigate this search space, such that they had the chances of finding something meaningful.
The optimization algorithm “Lion”, which beats the previous SOTA Adam on a majority of benchmarks.
Techniques to Restraint Search
They use a regularized evolution algorithm to search — adding a new statement, deleting a random statement, or modifying a statement by changing a function’s arguments.
Beyond this, they make several amendments to speed up the search process:
Only use assignment statements from variables and 45 common math functions like interpolation, multiplication etc. They experimented with conditionals and loops as well, but these didn’t yield much improvement.
This wouldn’t work for all kinds of problems, but is a good assumption for optimization algos.
Instead of starting from random, warm-start the initial values as AdamW to accelerate the search.
Prune redundancies like programs like syntax or type errors, functionally equivalent programs, or removing redundant statements (like those that would be overwritten later)
This is a classical Programming Languages techniques (check out equivalence graphs!)
Keep the proxy task that tests the quality of found algorithms very low-cost — testing more algorithms is better!
An interesting question raised here: can we meta-overfit? Find an algorithm that performs great on our proxy tasks and sucks in general?
To prevent this, they create a “funnel” of validation tasks. All good proxy tasks are put through target tasks of increasing size, up to 10^4x larger than the proxy task.
They observe that search experiments that meta-overfit later tend to uncover optimization algorithms that generalize better. Lesson: don’t prune too early — let it play out!
What’s up with Lion?
Here is Lion in its entirety.

Yeah, that’s really it. They perform a small analysis on Lion’s performance:
The sign operation adds noise to the updates and acts as a form of regularization. Evidence suggests Lion converges better in slower regions.
It uses less memory than Adam and others, since it only tracks the momentum. Having lesser steps, it also gives a performance speedup.
The two linear interpolation function let Lion remember longer gradient history while assigning a higher weight to a current gradient.
Lion also seems to prefer a larger batch size, with its optimal being 4096 vs Adam’s 256. This can be extremely useful in training larger sets of data.
Evaluation
The part you’ve all been waiting for. How well does Lion go up against Adam in some classic use cases? Here is Lion performance in Image Classification:
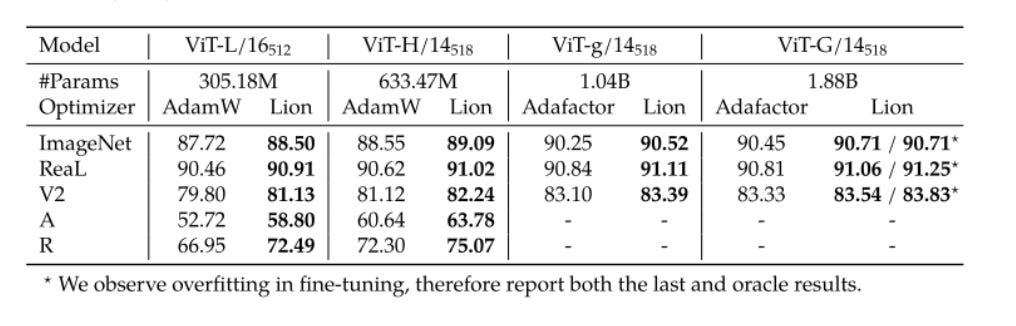
And here it is on language model training:

Measured against Adam in terms of ExaFLOPS, Lion is 3-5x faster.

Beyond this, Lion also seems to be more robust to hyper-parameter tuning, something that’s really important for adoption.
I looked very carefully through the entire paper, and could not find a single evidence of Adam beating Lion! It does seem like Lion is a strict improvement upon prior SOTA, which is quite an impressive achievement.
Limitations and Future Work
Since the evolution algorithm starts from Adam, it biases towards popular first-order “human” algorithms. It lacks the functionality necessary to break into advanced second-order algorithms, as a consequence of restricting the search space. Reducing this bias and improving search efficiency to find more novel algorithms is interesting future work.
On tasks where the datasets are massive and of high quality, there is a reduced difference between Adam and Lion. Similarly, strong augmentations close this gap as well. While Lion is good, for many use cases it might not be worth it in many cases to replace Adam.
Though people often scale up the batch size to enable more parallelism, it is likely that Lion performs no better than AdamW is the batch size is small.
Lion also requires momentum tracking, which can be expensive for training giant models. Future work could factorize the momentum to save memory.
In Summary
This paper is a great demonstration of the gap that exists between idea and execution. The idea “what if optimization algorithm finding was a search space” was simple enough. Half the paper talks about the tradeoffs they made to execute it practically. This is really powerful! The meat and potatoes of research is in bridging this gap.
Offloading important discoveries to computation has been a particularly recent trend. Finding faster matrix multiplication is another great example of this. The trend is clear — we’re hitting a level of compute availability such that machines, guided well, can make discoveries faster than humans reasoning from first principles.
Until next time!