
Distilling models makes them feasible to use
The importance of making models smaller

I love it when stars align — the AI controversy of the week is all about what we’re talking about today! Let me explain: Google recently came under fire about allegedly using ChatGPT data to train their newest public model, Bard. One of the techniques they used to do this is knowledge distillation.
The core idea is two-fold:
Training and inference have very different objectives. We want training to achieve correctness, even if it is cumbersome. We want inference to be fast, even if we have to sacrifice a couple percentage points of accuracy.
Similarly, we want to be able to learn from an intensely-trained model, and boil it down to a smaller model — even if the original trained model isn’t ours.
This is critical in making any AI technology consumer ready. So how can we do something like this?
Today, we’re reading “Distilling the Knowledge in a Neural Net” by Google, an old but crucial paper from 2015.
Introduction and Motivation
Goal: Compress a model into a smaller number of parameters, such that the decrease in accuracy from the decrease in parameters (and thus expressivity) is minimized.
Solution: Employ transfer learning. A smaller model learning from a bigger model will generalize better than a small model learning by itself.
Development Details

The core insight behind transfer learning is the idea of “soft labels”. Hard labels are what you’d think of as normal labels — a picture of a BMW has the label “car”. The smaller model is a student learning from the soft labels of the bigger teacher model.
How do we obtain soft labels? Let’s take a step back and talk about the softmax operation. The softmax operation is the last layer of basically every neural net, and looks something like this:

The motivation behind the softmax layer is that it turns a list of numbers to a probability distribution. Like the following:
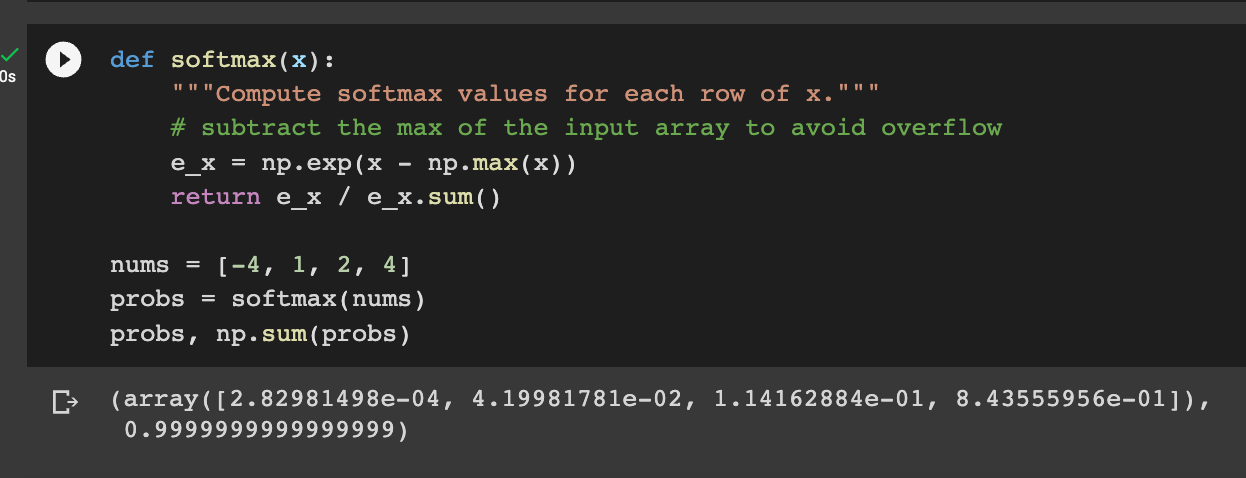
The problem — if the numbers are extreme, the probabilities get extreme.

So, we introduce this concept of “Temperature”. The higher the temperate, the smoother the softmax.


From here — we create a loss function between the soft label from the bigger model and the smaller model, added to the actual loss of the smaller model to the hard label. And that’s it — that’s transfer learning in knowledge distillation.
Evaluation
A simple MNIST test reveals the following: A normal small model makes 146 errors, and a big model makes 67 errors, but a small model with distillation makes 74 errors.
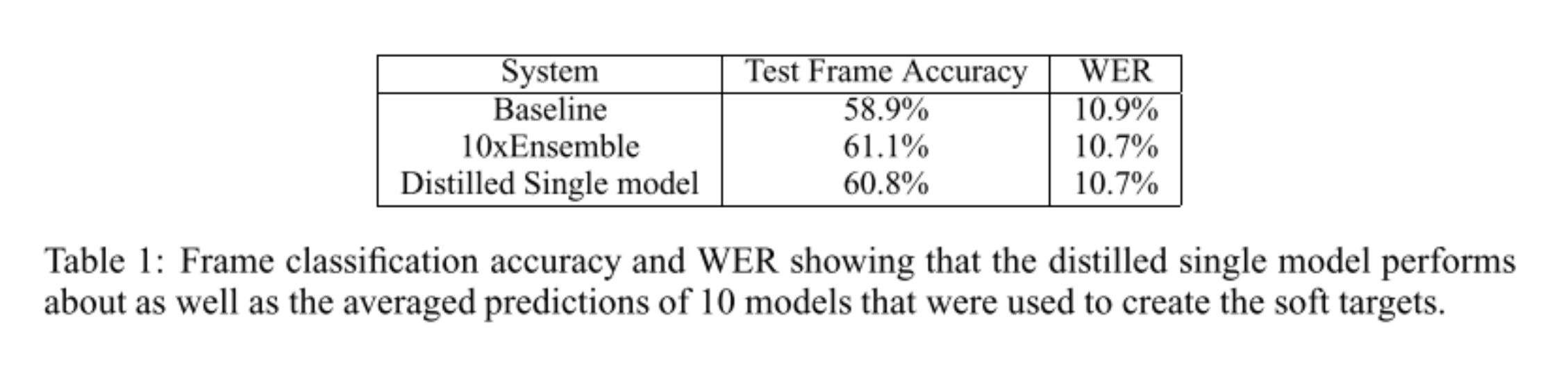
Tested on a speech recognition model, distillation yet again outperforms the baseline.
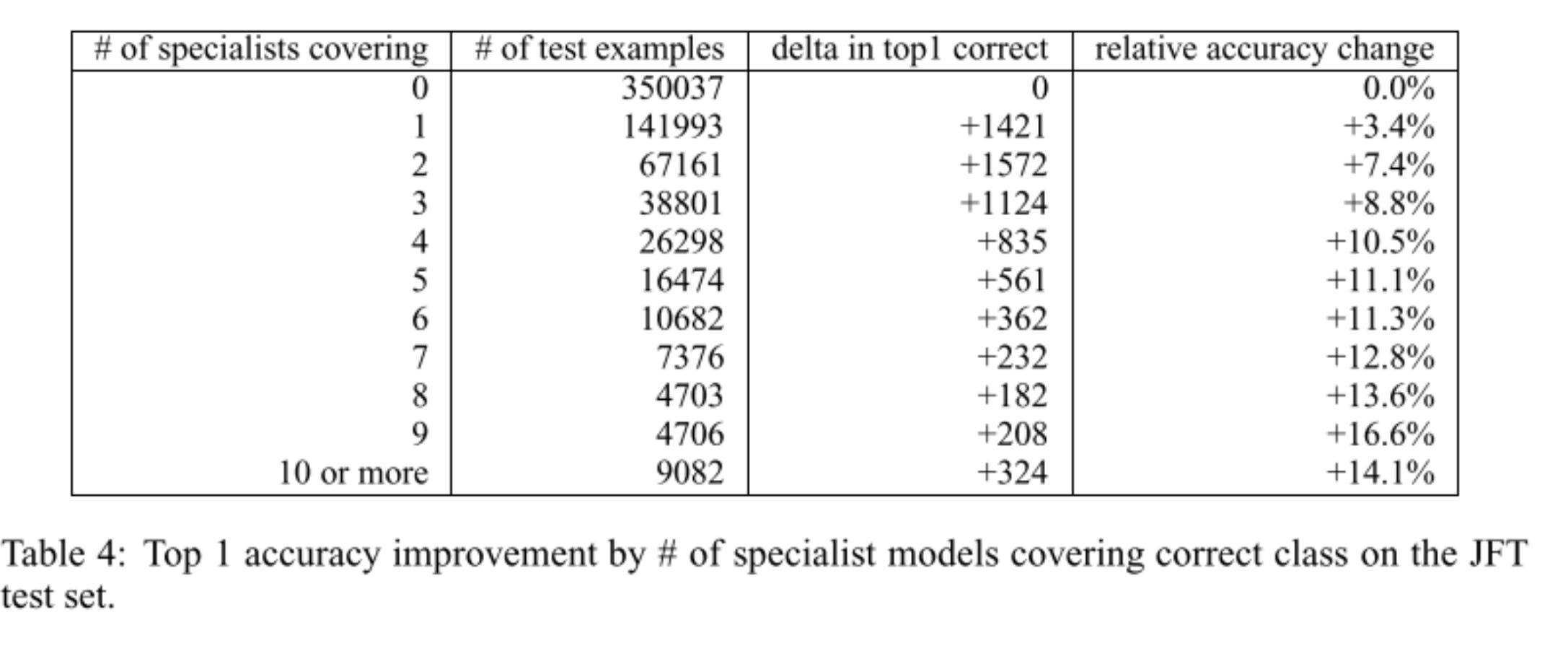
Demonstrated explicitly, we can see a relative accuracy change of anywhere between 3-14%, based on how many specialist models are used.
This paper is well before a lot of the ML benchmarks were created — so the amount of recognizable comparisons are quite minimal. However, from the evidence available, they make a pretty convincing argument that distillation is effective.
Limitations and Future Work
I’ll mention some commonly known limitations of knowledge distillation that were tackled in future research:
The performance of a student model trained using knowledge distillation is highly sensitive to the choice of hyperparameters. If the hyperparameters are not tuned carefully, the performance of the student model may suffer.
Increased training time — creating the smaller model is itself a time and resource consuming process, and future work has tackled attempting to optimize this process.
Recent work has attempted to incorporate knowledge distillation techniques with embedding spaces, such that the embedding space of a smaller model could be closer to that of a bigger one.
In Summary
Man, what a classic paper. This might be the shortest paper we’ve ever covered on the Daily Ink — exactly 8 pages. First-authored by the father of modern machine learning Geoffrey Hinton, you can expect high quality. This paper is a master class in presenting a simple, highly generalized idea with vast applicability.
What should you take away from it? The biggest concept is that of transfer learning — you can learn from a bigger model and transfer it’s abilities to a smaller model. You’ve already seen this in Alpaca and Llama, and I suspect you’ll see a lot more of it in the future.
Data is king in AI, but what happens when so much of AI training data is AI generated data?
Until next time!