
Google makes a language model for music
Text-to-music is finally here, and perhaps it even works.

Late last week, Google dropped a model that lit up Twitter with claims that they’d “solved music generation”. A look at their demos certainly seem to suggest that. Seriously, go take a look. It’s wild.
How did they pull this off? Let’s dive into the paper to understand.
Introduction and Motivation
There have been previous attempts to create a text-to-audio model by casting audio synthesis as a language modelling task. This allows these models (AudioLM) to achieve high-fidelity and long-term coherence.
Constraints: It is hard to map audio to text. Summarizing music is hard, and since music is a temporal medium, what is a good descriptor for minute 1 might be not good for minute 8. There just isn’t enough training data.
How can we train on a lot of unlabelled music, if we had a little bit of labelled music?
Solution: Project music and its corresponding text description to representations close to each other in an embedding space. During training, use the audio embedding. During inference, use the text embeddings. Then part of training can happen using only audio.
Development Details
First, the model is pre-trained to get three sets of embeddings — a music BERT, a text BERT, and MuLAN, which creates a mutual audio and text embedding.

During training, the co-optimized text and audio embeddings from LuLAN are taken. Then, there are two training phases:
Semantic Modelling: Learn a mapping from audio tokens to the semantic tokens.
Acoustic Modelling: Learn a mapping from audio and semantic tokens, to acoustic tokens.
Some clarifications: Think of the semantic tokens as a representation between the text and audio tokens. The difference between audio and acoustic tokens is that audio tokens are low-level representations of sound, while acoustic tokens are higher-level representations of music.

The inference is much simpler — The input text is converted to a text and a semantic embedding. Then audio is generated conditioned on those two embeddings (similar to the second phase mentioned above)

Don’t get lost in the technical jargon — at a high-level, what they’re doing is:
Create a vector space that text and sound both map to. Use your limited text-to-audio dataset to create this.
Training on sound tokens only, use your previously created space to embed sounds using your previous text-to-audio assumptions.
For example, unlabelled “funk” music would hopefully be embedded close to the labelled funk music, and you can leverage this.
For inference, cast whatever text you want to embeddings, and find the most probable acoustic tokens.
Evaluation
Here’s their results against other baselines:
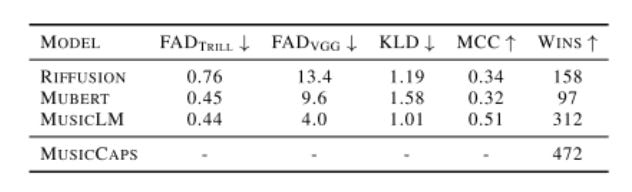
Some explanation is warranted — FAD is a metric that serves as a proxy for human perception. KL divergence suggests a lack of similarity to a provided reference music. Wins is a qualitative measure of comparing model outputs.
While not a landslide, MusicLM does improve on all metrics mentioned, and has the most qualitative wins.
Finally, they demonstrate that the model outputs bear less similarity to their input audio — suggesting that it isn’t just copying the training data, but understanding patterns and creating new music.

Limitations and Future Work
The model misunderstands negations and does not adhere to precise temporal ordering described in the text.
The qualitative evaluations provided in the paper that attempt to demonstrate the quality of the model are quite subjective, and “wins” is a very coarse metric. Further evaluation is needed.
Many of the quantitative metrics are also biased — MCC relies on the MuLan model, for example. This means it would be unsurprisingly favorable to MusicLM, a derivate of MuLan.
The vocal generation is the model’s weakest link, and perhaps generating lyrics alongside the music would assist the model is generating music with specific words. There is exciting future work in this domain.
To summarize – MusicLM is definitely a state-of-the-art model by Google, and the results speak for themselves. My intuition is that a simpler model, trained with more data, would outperform MusicLM’s complex training strategy. I also suspect that a temporal sequence like music is a better fit for a state space model or a diffusion model.
I’ll definitely be keeping an eye on this industry in the future — the potential is massive!