
Gradient Descent: The Ultimate Optimizer
NeurIPS 2022 Outstanding Paper Award

Introduction and Motivation
Problem: In machine learning, one must tune optimizer hyper-parameters, which is a trial-and-error process. Can we make this more methodical?
Previous Solution: To calculate ideal step size, compute optimal value by taking derivative of loss function wrt the step size.
Limitations to previous methods:
Manually differentiating optimizer update rules is tedious, error-prone.
The method only tunes the step size hyper-parameter.
The method introduces a new hyper-hyper-parameter, the hyper-step-size, which must also be tuned.
Core Contributions:
Automatic Differentiation to naturally optimize hyper-parameters, hyper-hyper-parameters, and so on. This resolves all the above three limitations.
Increased robustness to initial choice of hyper-parameters as the stack of hyper-parameters grows taller. A bad choice of a hyper-hyper-hyper-parameter more likely to converge than a bad choice of hyper-parameter.
Development Details
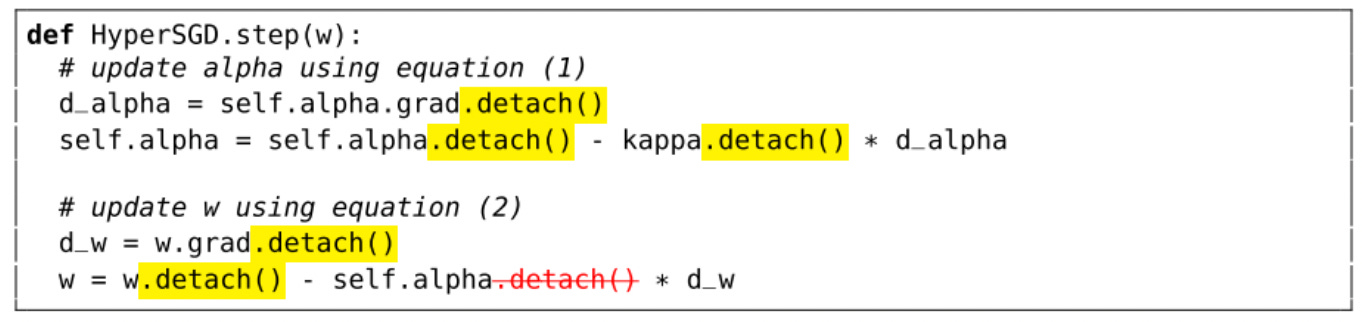
By detaching the hyper-parameters alpha and kappa when updating alpha, we can simply add this update as a step in backpropagation.

The recursive process follows from this technique.
Evaluation
The clearest example of the effectiveness of this technique is demonstrated using an RNN.
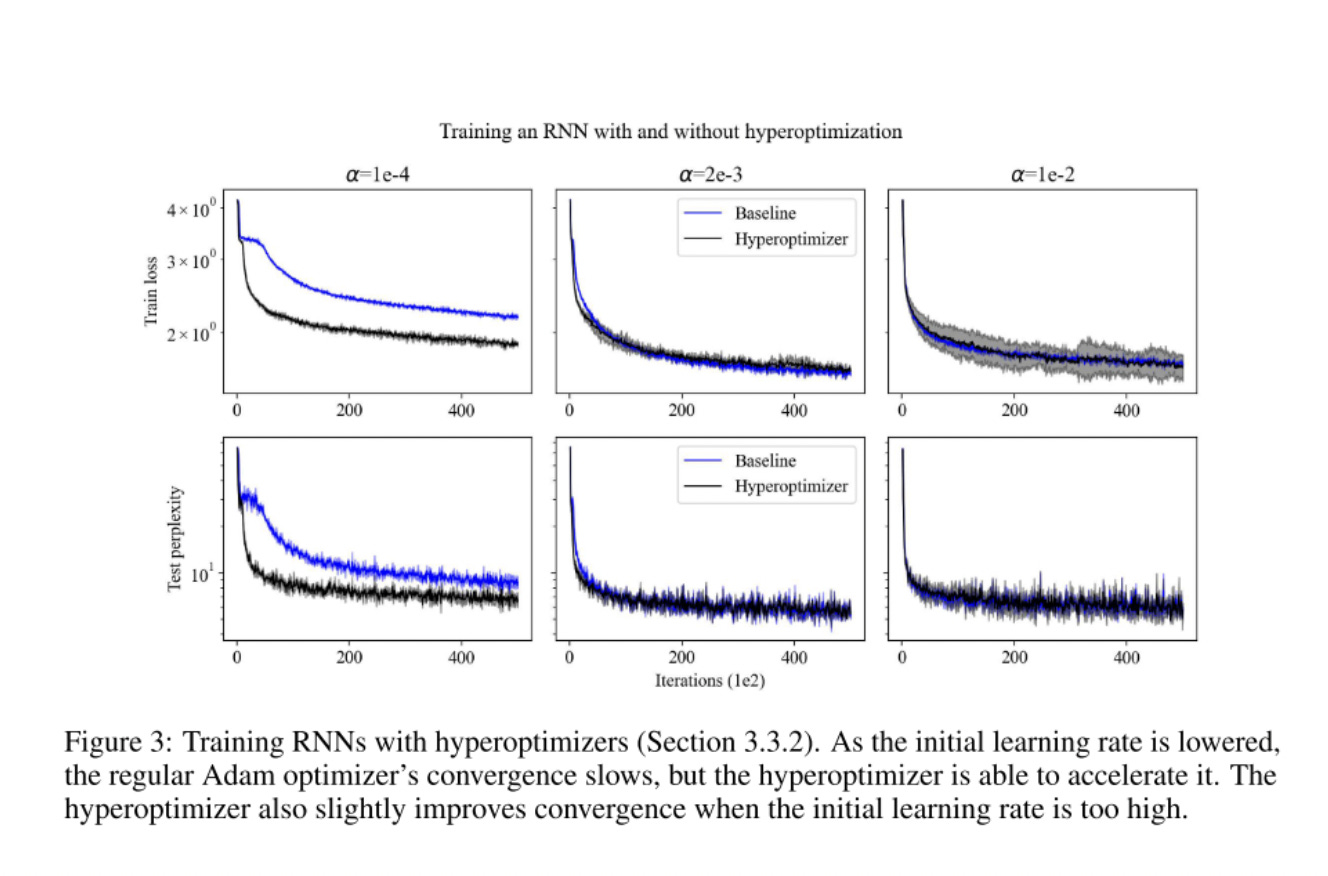
Notice how the hyper-optimized training loss converges so much faster. They also tested high resource networks, like a ResNet-152, to demonstrate that this technique is scalable
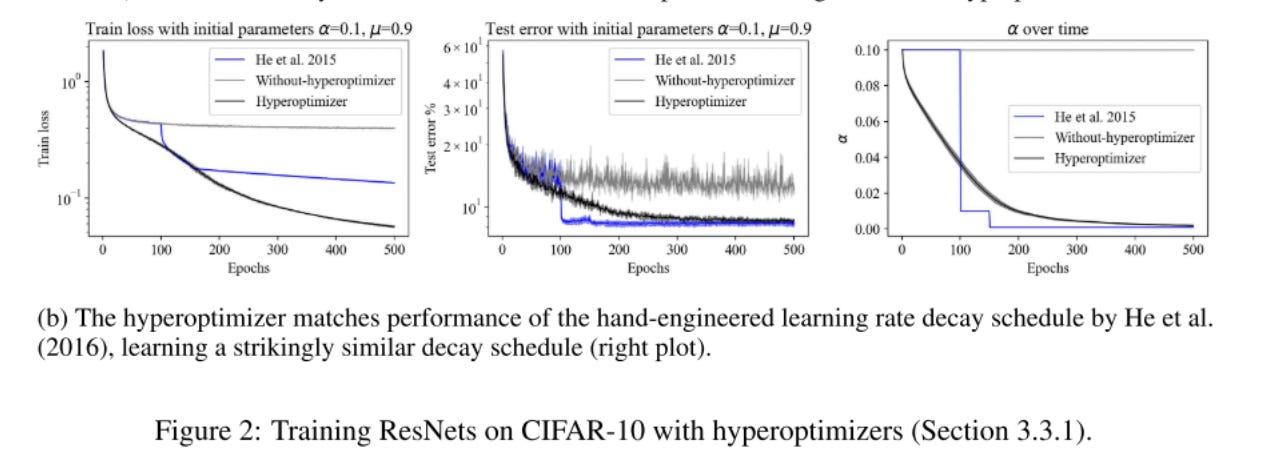
The paper demonstrates that their technique is comparable to the hand-engineering hyper-parameters in previous works, with only a three-level optimizer stack.
Limitations and Future Work
While such a technique does increase robustness, it cannot handle initial parameters set far too high — system becomes unstable and diverges.
Hard to integrate with systems that silently modify the computation graph like LSTMs, since these will disagree with their optimizer amendment mechanism.
A better language for expressing these is needed.