
Is a group of expert models better than one very smart model?
Google says yes, and it's more efficient as well

Most of the models we’ve seen to date have been “dense” models — this means that all the parameters used in training are also used in inference. Thus, training and deploying these model requires significant computing resources. Makes sense, doesn’t it? Imagine trying to make a person an expert on everything. That’ll take quite a few artificial neurons.
But there’s an alternative — having a series of specific experts, and choosing between them when relevant. This is a classical machine learning technique known as “mixture of experts”.

In this structure, even if the complete model is quite massive, only a subsection of it is activated for every training run. This means it is quite a bit more energy efficient.
This is the motivation behind Google’s new paper, “GLaM: Efficient Scaling of Language Models with Mixture of Experts”.
Introduction and Motivation
Goal: Can a sparse model with far fewer activated parameters perform as well as a dense model?
Solution: Use a mixture-of-experts structure to train the model. This allows them to give the model more capacity while limiting computation. Using this idea, they develop GLaM: A Generalist Language Model.
Through their work, they demonstrate that MoE models are more data and energy efficient than dense models.
Development Details
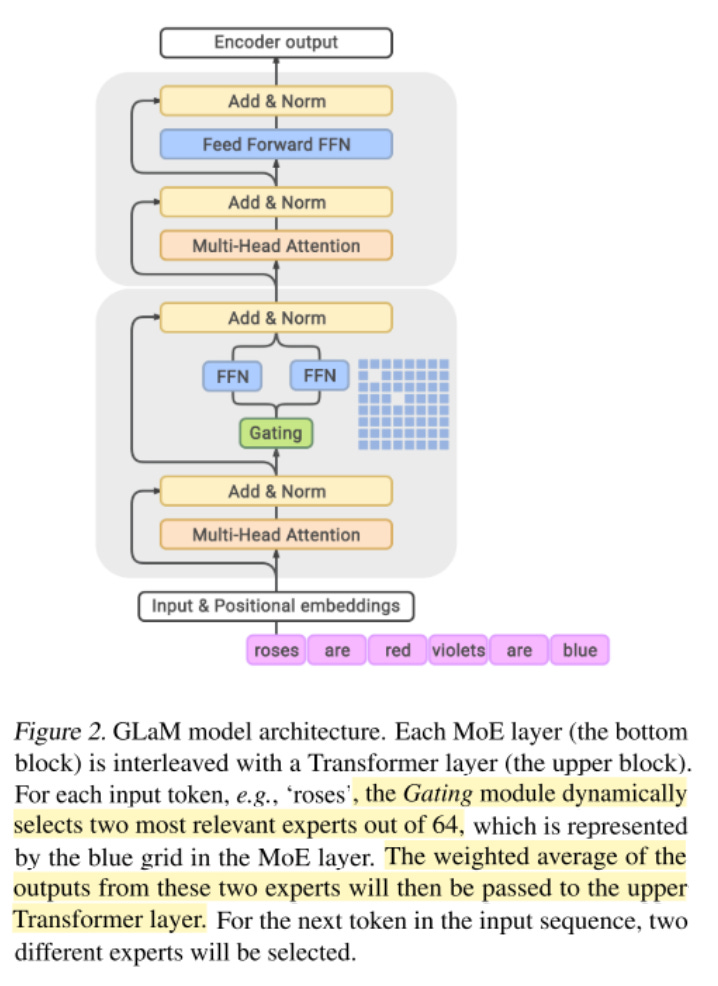
How does mixture of experts even work? There are 64 feed-forward-networks — our experts. There is a gating module which dynamically chooses experts to activate. The weighted average of the outputs from experts is used. A softmax activation function is used to model the probability distribution over when to use the experts.
Let’s take a look at the dataset as well. They’re data corpus is extremely big — 1.6 trillion tokens. They solve a problem that I’ve always wondered about — that all data is not created equal. It ranges from professional writing to low-quality comment and forum pages. Therefore, they train a text-quality classifier that produces a high-quality corpus out of the raw corpus. The end result:

Since they can train a mixture of experts model, they can give higher weights to bigger (but less frequent) data!
Evaluation
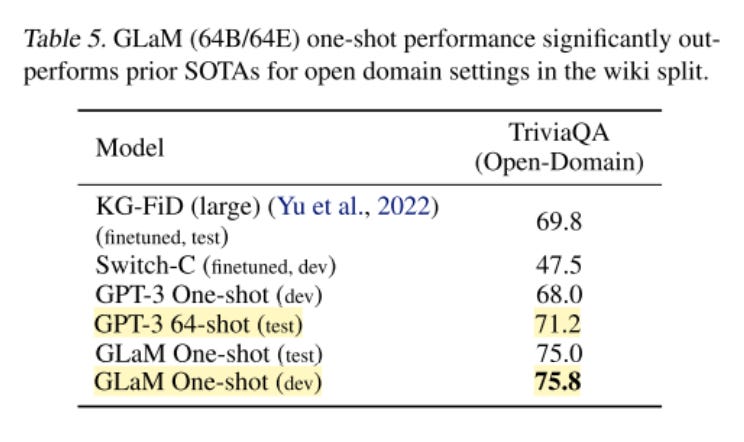
We’ve seen the TriviaQA dataset in the past — these are open question-answering benchmarks. GLaM outperforms previous SOTA (GPT-3) on this benchmark, even its fine-tuned version.
When measuring efficiency, we see that MoE models out-perform the dense models when measuring both training FLOPs (a unit of compute) and training tokens (a unit of data). These are measured on natural language generation and understanding tasks.

This suggests that mixture of experts have stronger inductive biases! Similar conclusions are suggested by their observation that GLaM MoE models perform consistently better than GLaM dense models for similar effective FLOPs per token.
Finally, we look at their small investigation into MoE scaling laws. They find that adding experts for a fixed computation per prediction budget generally means better performance.

Limitations and Future Work
I would love to see more insight into MoE scaling laws. This was not the focus of this paper, but I don’t think their appendix section on it paints a complete picture. For example, I would like to understand the performance dip going from 64 → 100 experts.
A lot of the discussion around MoE efficiency does not take into account the storage costs of serving a model with such high number of params, even if sparse. MoE models are especially bad when serving traffic is lower.
I would be interested in seeing MoE against smaller stronger models like Chinchilla, which are more data-optimal than GPT-3.
Not exactly a case of “what will Arushi find in the appendix this time?” exactly, but the appendix shows a complete comparison of GPT-3 and GLaM on all 29 benchmarks used in the GPT-3 paper, and it’s honestly pretty even. You would not infer that reading just the evaluation section.
In Summary
Ensembling techniques have been at the core of machine learning for a very long time. You see them in classical techniques like random forests, and in more modern structures like having multiple attention heads in transformers. Mixture of experts is an extension of this idea of ensembling.
I like that this paper puts so much emphasis on data and energy efficiency — I believe we are likely to hit soft and hard caps on these over the next few years, and we need to start thinking about more efficient systems now.
The core insight behind this paper is simple — ML models are great at specializing, and probability is a natural interface to dynamically choose between two expert models. Most future work emerges from keeping in mind what ML is good at, and then construct our architectures around that.
Until next time!