
Large models as engines of computation
Using models for more than just generation

If you’re reading this, I imagine you’re someone who enjoys reading thought-provoking ideas around technology, with a few corny jokes thrown in for good measure. In that case, I have a recommendation for you: every.to by Dan Shipper. An excellent newsletter. In particular, a recent post “GPT-4 is a Reasoning Engine” got fairly popular on Twitter the other day. A small exerpt:
Knowledge without reasoning is inert—you can’t do anything with it. But reasoning without knowledge can turn into compelling, confident fabrication.
This sounds fairly familiar — models do tend to hallucinate. But this is because there is no truth they are grounded in. If the model says the sky is blue, it doesn’t have the ability to look for a picture of the sky and verify that statement. If the model says Mozart is terrible, it can’t listen to Symphony No. 40 and confirm or deny that.
In part, models need to cross the barrier of modalities. It made me wonder: could models ever reason… across domains? Learn about text, and reason about music? If transformers have this magical ability to generalize, how far does it really go?
Today, we’re reading “Pre-trained Transformers as Universal Computation Engines”, by Berkeley AI Research and Google.
Introduction and Motivation
Goal: Investigate the capabilities of the transformation to generalize to other modalities with minimal fine-tuning.
Solution: Introduce the Frozen Pre-Trained Transformer (FPT) — a model that is fine-tuned on domain-specific data, but with most of the model frozen.

Core Insight: With most of the attention module frozen, the model is assumed to not be able to learn much from fine-tuning — it would have to rely on cross-modality pre-training and biases to perform these new tasks. If the skills really do generalize, then the FPT would do roughly as well as a normal trained transformer.
So… does it?
Evaluation
There are a lot of evals in this paper. Strap in. First, the big one. On common benchmarks, the FTP does just about as well as the full transformer — a very surprising observation.
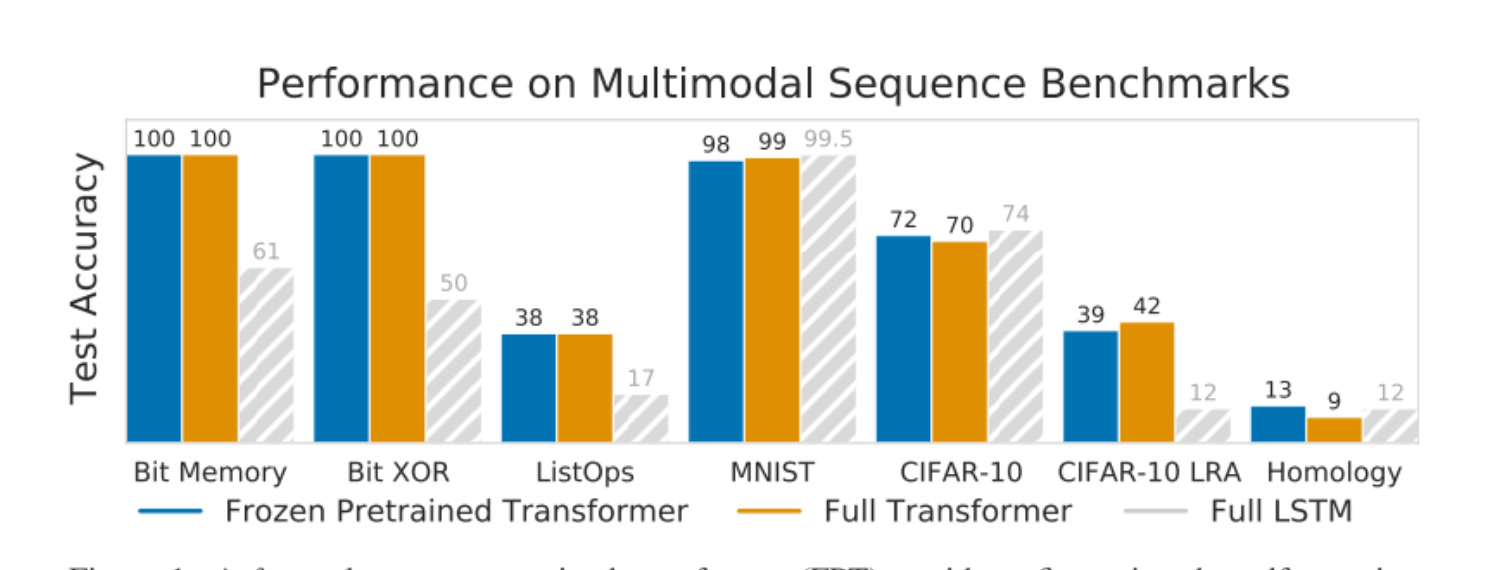
Next, they demonstrate that the base modality is important — language pre-training does the best. This is hypothesized to be by virtue of being the most data-rich domain, and thus possessing the model priors. The other bases are bit memory training, vision transformers, and random initialization.

They also demonstrate that this technique of freezing the transformer is more compute and time efficient. Imagine a scenario in which we have to spin up a lot of fine-tuned transformers — then the speedups really matter.

Finally, they demonstrate that the model is in-fact, attending to the right things in fine-tuning. Here is a language transformer applied to bit XOR tasks, and it correctly attends to the bits to generate the XOR value.

Limitations and Future Work
Look back at Table 2, marking the test accuracy of different fine-tuned transformer. It is very surprising just how high the random transformer is. A random transformer is one in which initialization of the frozen transformer parameters randomly using the default initialization choices for GPT-2, i.e. without pre-training.

This suggests a strong claim against the claim of the paper — that pre-training is helping these models succeed in cross-modal tasks. I wish this was explored more.
I did think their testing tasks were perhaps a bit too simple — MNIST and XOR and CIFAR-10 are good empirical evidence for a hypothesis, but not substantial for a proof in my opinion. I would love to see this work extended to more competitive benchmarks such as ImageNet or MMLU in the future.
They are a small comparison table with the performance of other transformer models as well.

I found this data to be extremely surprising, and a bit confusing. Future work could look into what architectural choices help models generalize across domains better.

In Summary
I quite like empirical papers like this — there are so many things we do not understand about model behavior, and to test their abilities is to further invite questions into the “why” behind models. It also helps us create better future models, particularly suited for multi-modality! (cough GPT-4 cough).
I do wish this paper had made clear why the Frozen Transformer is an important contribution — I was not convinced that the impressive performance of the frozen transformer implied inherent cross-domain ability, demotivated by the great performance of also the random transformer.
I do look forward to more multi-modal transformer research in the future. It is obvious that more information domains lead to more well-rounded and grounded models.
Until next time!