
Make models smarter not larger, with data pruning
Beyond neural scaling laws: beating power law scaling via data pruning

Introduction and Motivation
Unless you run a large research lab like Google Brain, DeepMind, OpenAI, or something similar, you do not have the resources necessary to run today’s state-of-the-art language models.
Recent models have further continued to scale up, given evidence from neural scaling laws [2][3]. However, this is extremely computationally and monetarily expensive.
Goal: Break beyond power law scaling with access to a high-quality data pruning metric ranking order in which training examples should be discarded. Stop throwing random data at our models.
Constraint: Most existing high-performing pruning metrics scale poorly, and the best are computationally intensive and require labels.
Core Contribution: Develop a new simple, cheap, and scalable self-supervised pruning metric that demonstrates comparable performance to the best supervised metrics.
Core Insight: Many training examples are highly redundant.
Development Details
Self-supervised data pruning is achieved through a prototypicality metric.
They perform k-means clustering in the embedding space of an ImageNet pre-trained self-supervised model.
The difficulty of each data point is defined by the cosine distance to its’s nearest cluster centroid (prototype).
The easier the problem, the more prototypical it is (and vice-versa).
As the size of the dataset decreases, keep harder and less prototypical problems.
I particularly like this idea, for how intuitive it is! The paper admits that this was supposed to be “just another pruning metric” alongside the others, but surprisingly outperformed all supervised metrics, including the best one (memorization).
Evaluation
Empirical evidence shows that data pruning improves transfer learning. The paper pre-trained a model on selected data from ImageNet, and demonstrated an equivalent or better performance of CIFAR-10 than if model was pre-trained on all of ImageNet.

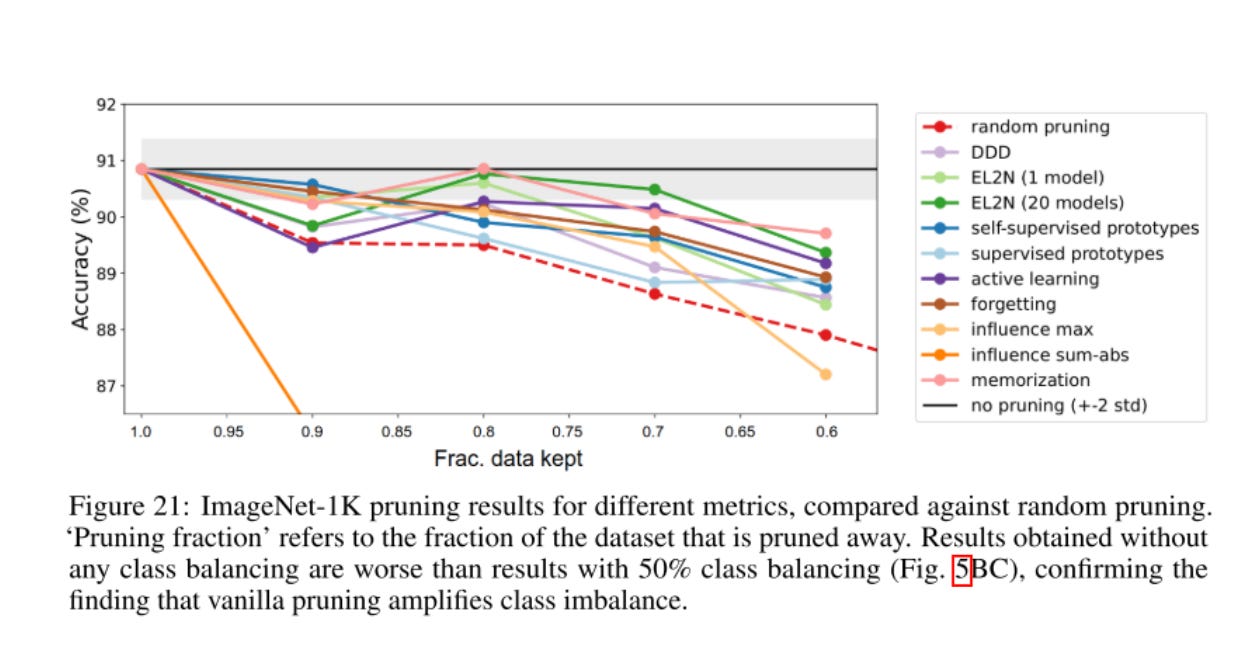
All previously existing pruning metrics amplify class imbalance, which results in degraded performance.
They demonstrated that one can discard 20% of ImageNet without sacrificing performance, using a self-supervised metric that is on par with the best and most computationally expensive supervised metric.
Limitations and Future Work
Achieving exponential scaling requires a very high quality data pruning metric.
The goal of data pruning is to decrease computation cost. But practically, use of pruning seems to necessitate an increase in training epochs (to hold number of iterations over dataset constant). This tradeoff in resource must be more carefully examined, to determine whether data pruning is beneficial at all.
Class balancing was essential to maintain performance of data subsets. Currently, they use the simple approach of 50% of each class being pruned. In the future, a self-supervised version of class balancing would be needed. Currently, this method is ineffective on large-scale unlabeled datasets

.
With class imbalance, the self-supervised version barely does better than random pruning.
Something interesting demonstrated here is that in Figure C above, random pruning is not too far away from other pruning techniques. One would expect it to perform much worse! While such techniques do demonstrate clear improvements, the promise of “exponential scaling” is still clearly theoretical. It would be interesting to see empirical evidence of theoretical exponential scaling.
Note: A substantial amount of this paper is quite theoretical. I abstract away those sections and focus on their practical applications in this summary. Refer to the paper if you’d like to read the theory itself.
Criticism of the Paper
An important remark is that a core contribution mentioned by the paper is the following: “We leveraged self-supervised learning to develop a new, cheap unsupervised data pruning metric that does not require labels, unlike prior methods.”
As demonstrated by the limitations section, this claim is a stretch. To achieve comparable performance, the method does use labels (in class balancing), even though it does not technically require them. Without using labels, their method is beaten by various previous techniques like EL2N, memorization, and forgetting.
References
[1] Paper link: https://arxiv.org/abs/2206.14486