
Models can magically learn new skills at scale
The mysterious emergent abilities of LLMs

Have you ever wondered how GPT-3 can do such wonderful things? How ChatGPT is somehow better? In fact, let’s run some tests real fast:
The classic GPT-3 writes poems like I did in high school, while ChatGPT is much better, and seems to understand the concept of rhymes!

Those amongst you who’ve been following this series for a while and read my ChatGPT breakdown would call me out — this isn’t about scale! This is because ChatGPT uses reinforcement learning! And you’d be right!
So let’s take another example Of Arithmetic! We compare a small GPT model Ada to a larger model Babbage to their largest model Davinci. None of these are trained with RL, and yet:

Ada’s spitting out non-sense. Babbage gets closer but still not quite there. And then BAM! DaVinci gets it in one go. All of these are training on the same data! What’s going on here?
Today, we discuss “Emergent Abilities of Large Language Models”.
Introduction and Motivation
Core Claim: As models are scaled up, the downstream performance on tasks does not grow continuously but has a sudden jump. This means that we cannot predict what larger models will be able to do by extrapolating from smaller models.
Development Details
What is scale? ML models are parameterized by three properties of their training:
Model size: Number of parameters in the model
Data size: Number of tokens in the training data
Compute size: Number of FloPs (Floating point operations) the model was trained for
These metrics are not the same, but are heavily correlated — bigger models are trained with more compute, for example. The paper defines scale as some combination of these.
Evaluation
The core of this paper is the data collected, so let’s view it!

Across many tasks, we notice that the performance is quite random, until we cross a threshold of model scale (here, training FLOPs). Then, the ability of the model jumps to on average ~20% above random (statistically significant!). 5 * 10^23 FLOPS seems to be the magic number for many thresholds.
The Word in Context (bottom-right) benchmark is very interesting, however. GPT-3 and Chinchilla (2 SOTA models) fail to rise above random even past the magic threshold. While this might put doubt on the power of scaling, above-random performance eventually emerged when PaLM was scaled to 2.5 * 10^24 FLOPs (540B parameters), much larger than GPT-3 and Chinchilla.
Prompting methods like scratchpad, instruction-finetuning or chain-of-thought reasoning also show similar patterns — smaller models don’t benefit from them, until a threshold, and then they demonstrate massive returns.
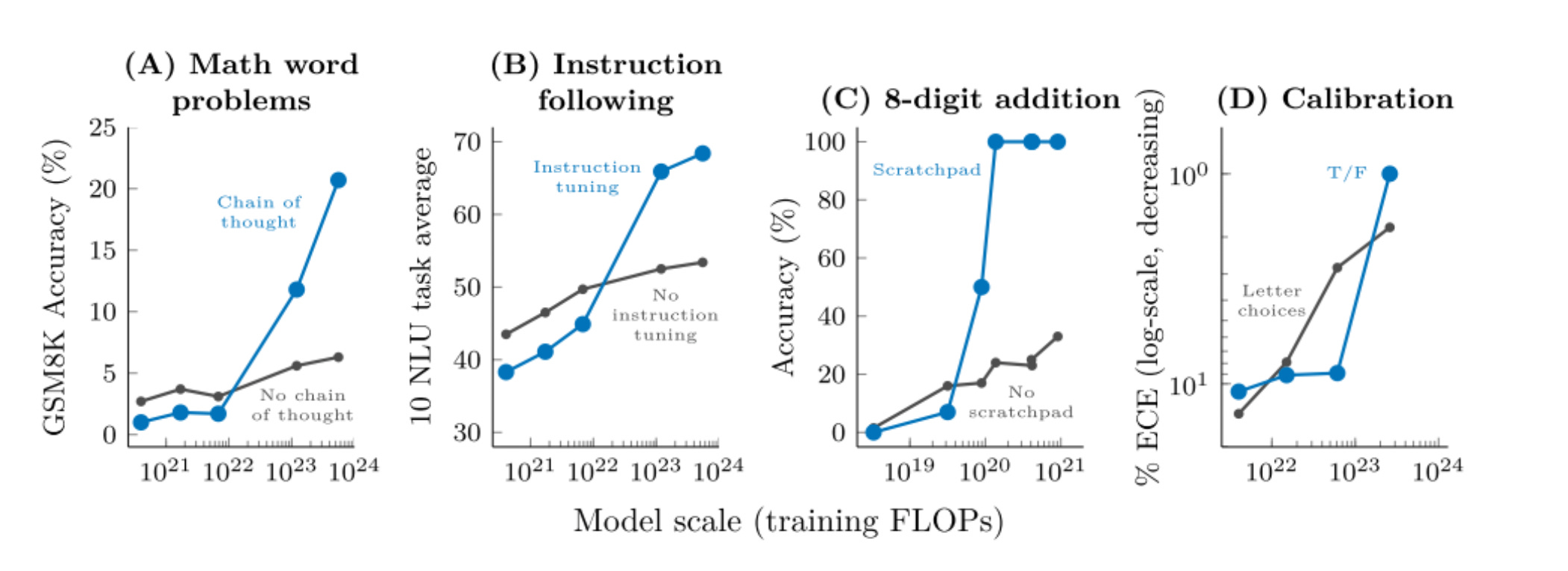
Some might argue that smaller models do show these abilities, and our metrics are not capturing it. The simple counter to that is that classification tasks also show emergent abilities, which are all or nothing.
Limitations and Future Work
Further scaling: If scale is magical, the obvious next step is to scale it up even more to see if and when we stop seeing emergent abilities. This is challenging, however, since current models already train on a good chunk of the internet. This means bigger models as well as more data are likely in our future.
There are some tasks at which these models still don’t perform any better than random — often problems with abstract reasoning. Further research can investigate why these abilities haven’t emerged yet.
An investigation of cross-entropy loss, generative task metrics (like BLEU or ROUGE) and type of tasks was not enough to develop a theory for why emergence happens. Understanding emergence is an important direction of future work.
A Big Caveat: Hello and welcome back to what can Arushi find in the appendix? And today, we turn our attention all the way to Appendix F, where the authors highlight that there are many tasks where PaLM 62B is emergent but bigger models GPT-3 and LaMDA are not. Not sure why this is in the appendix, since this is a crucial observation in the correlation between scale and emergence.
In Summary
I tend to try not to be negative about papers — research is fun and important and should be encouraged! However, I feel firmly like this is half a paper — it provides a lot of data, but does not make any claim about what that data means. It suggests a correlation between scale and emergence, but hides counterexamples and does not try to explain exceptions. It suggests metrics to define emergence (like cross-entropy loss) but moves those to the Appendix and admits that correlation is not statistically significant.
Despite my complaints, it is still extremely valuable to highlight how such models have “emergent abilities”. Understanding how emergence occurs will be crucial to improving model performance once we hit the metaphorical cap on training FLOPs. In the meantime, if you’ve ever wondered why companies like Google and OpenAI are willing to throw this much money to make bigger and bigger models, now you know.
Until next time!