
Multi-modal models are the future
Google sticks a robot onto an LLM, or an LLM onto a robot

At this point, you know about GPT-4. You’ve probably messed around with it, and it is quite awesome. I used it to help with Econ homework the other day (shh). Things are getting whacky in a hurry. I’d write a paper on it but the technical report they shared might as well have "source: trust me bro" plastered across it.
What I’m most excited for, however, is the multi-modality of the model. In the developer demo, Greg Brockman demonstrated the model’s image capabilities. It accepts a hand-drawn sketch and makes a whole website out of it. So cool.
In all the hype around GPT-4, there was a little project that went under the radar. By Google, it attempted to merge language models and robotic data together, to make a model that could understand English, images, and sensory data.

Today, we’re reading “Palm-E: An Embodied Multimodal Language Model”.
Introduction and Motivation
Goal: Combine image and sensory data gathered by the model with a language model’s capabilities to emit a sequence of actions for a task.

Constraints: Keen readers would remember a similar project we’ve covered before — PaLMSayCan, also by Google. In that project, they attempted to make two models talk to each other: one suggested ideas and the other rated their validity and executed them, creating a feedback loop.

The problem: They show in the paper that this structure is not enough. The models often didn’t talk very well. Obvious tasks were rated invalid, the idea suggester jumped steps and the executor model got confused.
The Solution: Instead of the modality of conversation between the robots and the model being English, inject images and sensory data from the robot into the same embedding space as that of the language model.
Development Details
What does “injecting images into an embedding space” even mean? A latent embedding space is the internal representation of words for a language model. In an embedding space, the vector representations of “king” and “crown” would be embedded close to each other, since they appear with each other quite often.
Images and sensory data can have vector representations too. And if they are in the same dimension as that of the words, they can share an embedding space. This seems like a crazy concept, until you realize that a model doesn’t understand the difference between images and words. They are all numbers to the neural net. Therefore, it can learn from images, words, and sensory data all-together.

So we get a model that can do many, many things. The output of the model is in English, and can be thought of a high-level policy. It is handed to the robot, which can then execute this policy.
However, these policies are not enough to solve long-horizon tasks just by themselves. Therefore, this is integrated into a control loop, where decisions are executed by a robot, and new observations are returned to make new predictions (quite like the PaLM-SayCan model).
Evaluation
First, let’s view PaLM-E in the context of previous work. It crushes many standard benchmarks.

But some of the more interesting evaluations are much more specific. For training the model, they use a “mixture” technique — using multiple types of data (3D reconstruction, validity model) to train. This is an example of “transfer learning” — different data domains support each other, and overall performance spikes.

The full-mixture + fine-tuning does better than any one single robot.
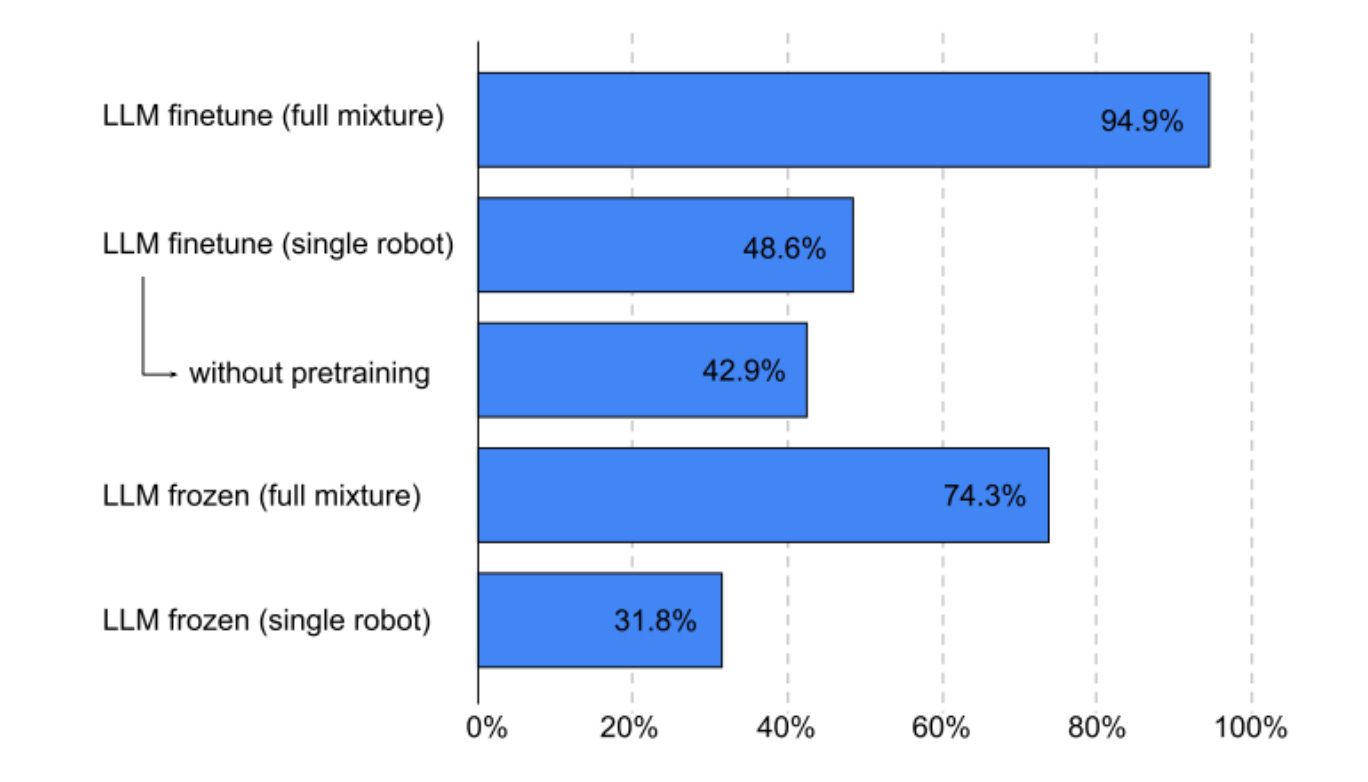
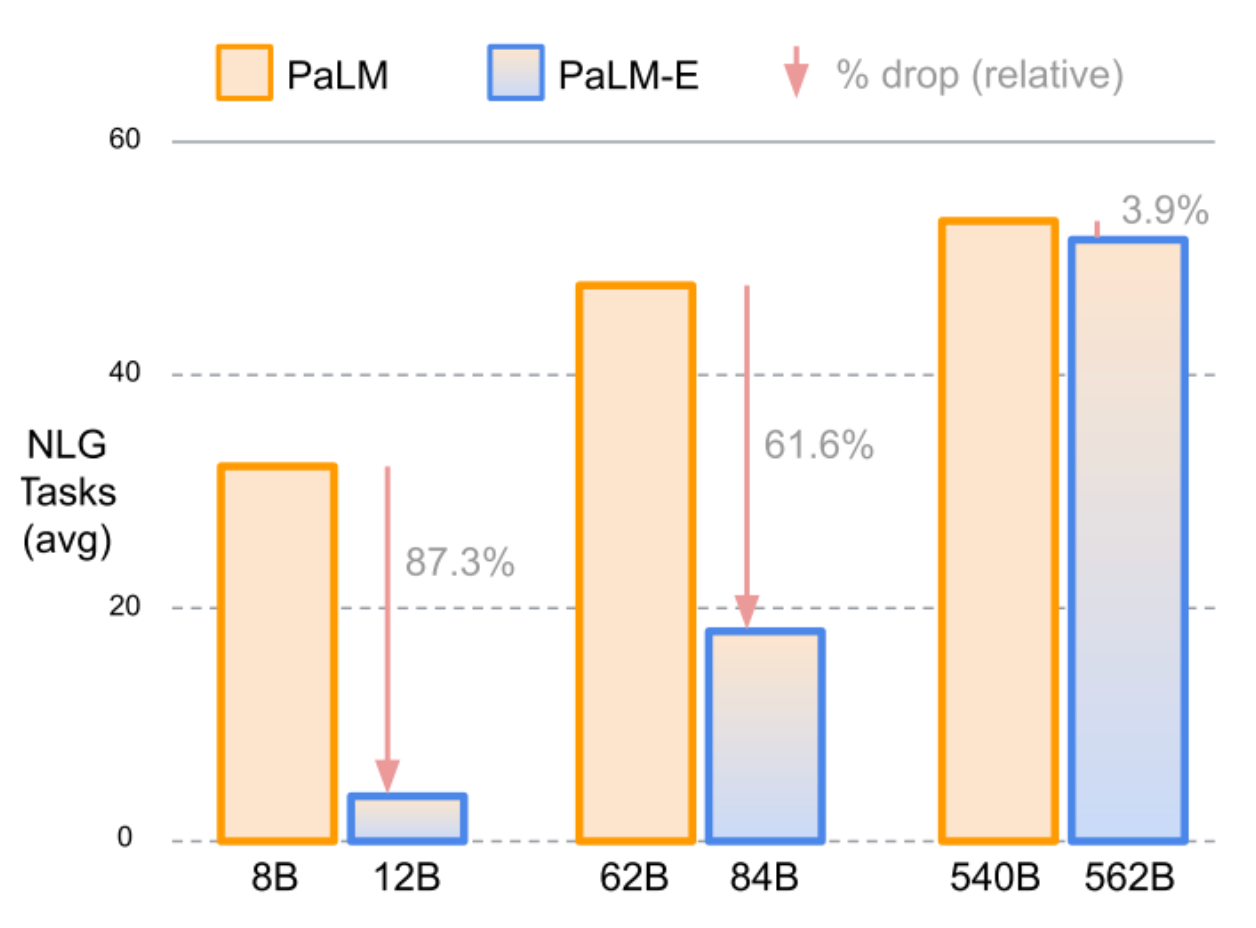
While there is some degradation of specific abilities like natural language understanding and visual understanding, these are much less pronounced in larger models.
I’d massively recommend going to their website to see the demos in action!! Watching robots move around and accomplish tasks like fetching chips is always a great way to spend the evening.
Limitations and Future Work
I think robots have a massive potential to be bi-directional training systems — a model that is free to roam is a source of visual data to improve visual models with, and of course for sensory data. Successful actions even give us fine-tuning data for supervised learning. I believe robots will be used very soon to help models be more data efficient.
It is interesting to me that the robot had to be put into a control-loop despite the integration — I would love to see future work try to integrate the looped nature of robotics into the model architecture itself, which would allow it to learn how to iterate more naturally.
I don’t think most people realize how big a 562B parameter model is. It is insane. It requires ~30 GPUs to simply fit the model, never mind the training or inference data. This is possible for no one except Google, and is especially impossible for edge devices. It is clear that robotic language models require more inductive biases to be more parameter-efficient.
In Summary
I like this paper! The core insight of using a single embedding space is simple yet effective. However, I worry that the model’s success is simply a factor of scale, not of the underlying technique. Smaller versions of PaLM-E are promising, but not anywhere nearly as impressive.
What should you take away from this paper? One of the most fundamental ideas in machine learning: Anything you can represent as numbers, you can make a model learn. Anything two things you can make a model learn, you can make a model learn in conjunction.
This is the secret to unlocking multi-modality.
Until next time!