
Optimal parallelism in ML training is possible, says ALPA
Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning

You might heard of data parallelism in model training before. The core idea — have multiple copies of your model, train different data on them, average the gradients, update all weights.

That is not what we’re talking about today. We’re talking about model parallelism. Most ML models that you’ve heard about (ChatGPT, Claude, Cohere, Adept, LaMDA and so on…) are not trained on one machine. GPT (175B params) famously needs at least 8 GPUs to just fit the size of the model.
Introduction and Motivation
Since the model needs to be divided into many parts spread over many machines, what is the best way to split the model?
There’s two core ways to do it:

Inter-operator parallelism: If there are two operations A and B that are part of the computation graph — A goes on one machine and B goes on another.
Intra-operator parallelism: Given an operation A, half of it could be computed on one machine and the other half on another.
Goal: Given a computation graph that represents a neural network, what combination of intra and inter-operator parallelism gives us the fastest training structure?
Core Insight: Machines in a cluster communicate fast, machine across clusters communicate slow. Intra-operator parallelism has to communicate a lot more than inter-operator parallelism. Therefore, optimize for intra-operator within a cluster and inter-operator across clusters.
Development Details
At a high-level, ALPA does the following:
First, the model uses dynamic programming to split the computation graph across clusters, putting different sets of operations in different clusters.
Next, the model uses integer linear programming to optimize the intra-operator parallelism within a cluster, considering only the subgraph generated in the first step.
These are co-optimized — the DP algorithm finds the division that minimizes the cost/speed of the ILP split in all the clusters.
Evaluation
Their testbed consisted of 8 nodes and 64 GPUs. We want the throughput to increase as the number of GPUs used in the model increases. We see that, when tested against state-of-the-art expert-written parallelism, Alpa is competitive and on occasion better.
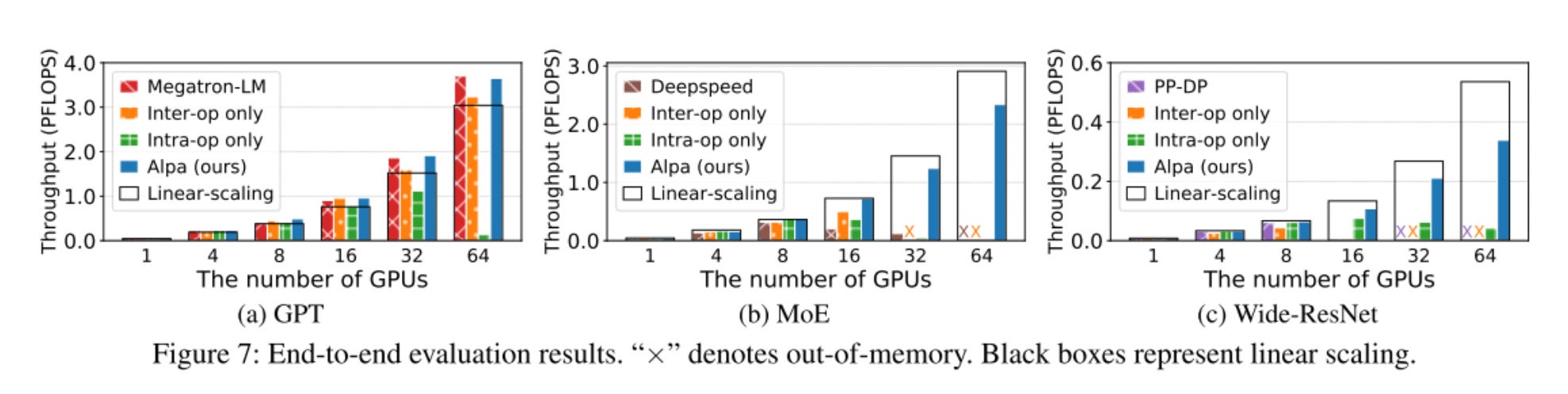
They also show that casting the intra-operator parallelism as an ILP problem was clearly the correct mechanism, and it scales better than other previous techniques.
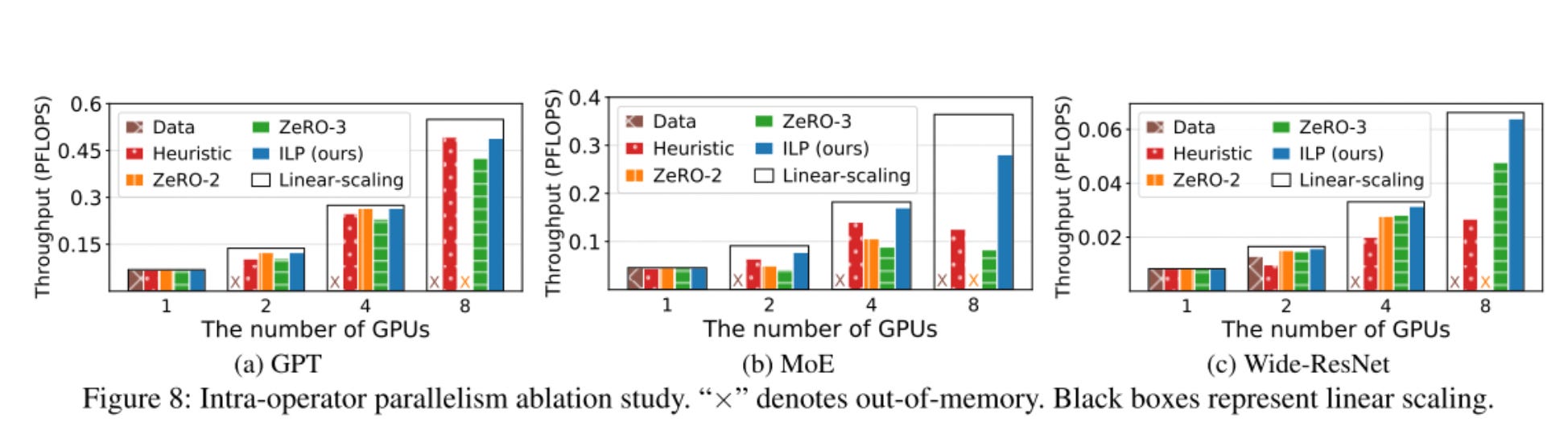
Limitations and Future Work
I would have liked to see more testing against other models except GPT at larger scales. While out-of-memory is an unrecoverable error, it doesn’t make for the fairest testing mechanisms.
In the ILP formulation for intra-operator parallelism, a lot of smaller operators were discarded to simply to the point that the ILP calculation is tractable (completed in an hour). There is a possibility of improving the accuracy of this by allowing a variable granularity in the ILP detail.
Currently, the paper assumes that clusters communicate fast and cross-cluster communication is slow. While this view does work for them, networking is a lot more complicated than this simple binary. There is future work possible to profiling the network and using that information to create a more realistically optimal system.
In practice, the set of machines that a model is trained on are rarely constant, and the networking between them even more variable. There is work to be done in the online evaluation of automatic parallelism, instead of keeping this step offline.
In summary — I think Alpa is a big step in the right direction. Parallelism doesn’t need to be heuristic driven, or expert-written. The casting of the parallelism problem as a dynamic programming problem is quite inspired. I think this is a great first step, and see a lot of potential in exciting future work. There is still a ways to go before such a model yields the truly optimal parallelism strategy, but I believe we are well on our way there.