
Teaching computers to think in abstractions
Dreamcoder: Growing generalizable, interpretable knowledge with wake-sleep Bayesian program learning

Introduction and Motivation
We have gotten quite good at making smart systems for specific programming domains — such that a lot of neural PL is designing “DSL”s or domain specific languages. But this is clearly not infinitely scalable.
Goal: How can we make learning systems that adapt themselves to new domains?
Core Insight: By “library learning” — learning routines through solving programs that can then be used to solve other programs.
An example: We first learn how to sort a list. Then, when asked to get the maximum element of a list, we can use our sort function and return the first element. This use of “abstracted routines” makes the program synthesis process possible and efficient.
Development Details
The DreamCoder algorithm exists in three phases:

Wake Phase: Given some “recognition model” that recognizes what the task is asking for and what routines to use from the library, we find the best programs for the task until we find one that solves the task.
Sleep Abstraction Phase: Given the problems solved in the wake phase, look for common patterns. Are we adding 1 to variables often? Maybe we’re subtracting one and making a recursive call very often as well. Pull out these “common trends” and add them to our library.
Sleep Dreaming Phase: Given some problems we’ve solved, come up with new problems to solve and solve it. This is the machine dreaming of problems to solve. These problems and solutions continue to train the recognition model to get better at recognizing the patterns in the task.
So, let’s understand at a high level— start with some library, solve problems, understand common structures and add them to the library, add the problems and solutions to your understanding of how to solve other problems, continue solving problems and repeat.
Very human-like, isn’t it?
Evaluation
Testing on the 2017 SyGuS program synthesis competition:
DreamCoder solves 3.7% of the problems within 10 minutes with an average search time of 235 seconds
After learning, it solves 79.6%, and does so much faster, solving them in an average of 40 seconds
The best-performing synthesizer in this competition (CVC4) solved 82.4% of the problems — but here, the competition conditions are 1 hour & 8 CPUs per problem, and with this more generous compute budget we solve 84.3% of the problems.
SyGuS additionally comes with a different hand-engineered library of primitives for each text editing problem. Here we learned a single library of text-editing concepts that applied generically to any editing task, a prerequisite for real-world use. Thus, this success is even more impressive than just the numbers.
In terms of ablation studies, they show that the full model with both sleep phases gives the best results. Moreover, we observe that the full model creates deeper libraries — that is, creating higher levels of abstractions than the non-dreaming counterpart.

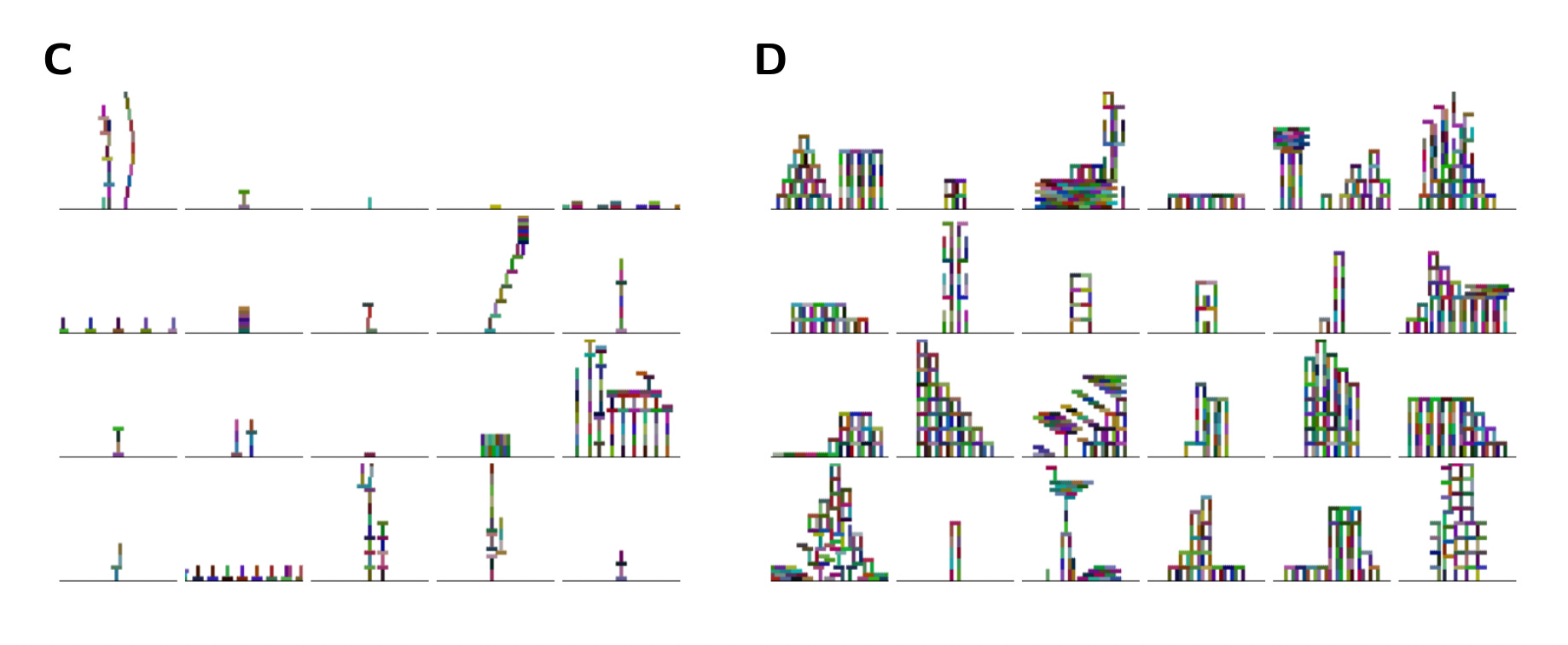
Finally, some fun pictures — it is quite exciting to see what the model can do in the more artistic domain.
Here, they demonstrate the quality of the designs the model can make before and after learning.
They also discover that the model can learn fundamental mathematical principles from basic axioms, which is very impressive as well.
Limitations and Future Work
Compute requirements: The compute requirements to create basic functions like sort/filter are quite high, and one can imagine that they would become intractable with an even deeper library and more complicated problems.
Slowness: It is also important to note that this process is quite slow, taking ~24 hours to solve problems.
Random Fantasies: In the dreaming phase, the fantasies are generated at random — there is no distinction between good and bad problems. The library generator could develop much more relevant libraries if it sourced problems externally instead of randomizing them.
The work focuses on problem-solving domains where the solution space is largely captured by crisp symbolic forms. Much real-world data is far messier than considered here.
References
[1] Paper link: https://arxiv.org/abs/2006.08381