
Teaching LLMs to use tools and not suck at math
And maybe then they'll figure out how to 2 + 3

Language models cannot do basic arithmetic, and are therefore memed on very often. For all their magical abilities, it feels very surprising that smaller models outperform them in this so much.
In other models like LaMDA, we see the introduction of a “toolbox” — allowing LLMs to deploy some tasks to calculators and APIs, where they perform worse. Toolformer introduces a standardized way to do so.
Introduction and Motivation
Goal: Create a model trained to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction.
Problem: Existing approaches rely on large amounts of human annotations or limit tool use to task-specific settings only. Want a self-supervising way to learn tool adoption.
Constraint: The LM should not lose any of its generality, cleverly deciding when and how to use which tool. If the model is worse, the tools don’t make sense.
Solution: Use in-context learning to generate entire datasets from scratch using the model itself.
Development Details

Here’s how the model generates its self-annotated dataset:
Give the model a handful of human-written examples of an API usage.
Let the LM annotate a huge language dataset with potential calls.
Use self-supervised loss to determine which calls help the model in predicting future tokens. Between a call and no call, whichever minimizes total loss is chosen.
Finetune the LM itself on API calls that it considers useful.
They give a good example demonstrating how the model works":

Evaluation
On evaluation benchmark LAMA — particularly the subset where the model is tasked with completing a short statement with a missing fact, they demonstrate that Toolformer 6.7B is competitive with much larger models.

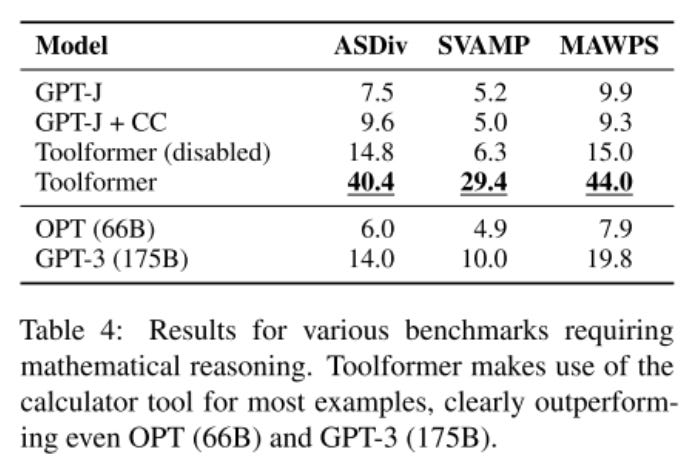
Similarly, it does better on mathematical problems.
.However, it surprisingly does not outperform GPT-3 on question-answering datasets.

The paper claims this is because of the simplicity of their search engine which yields many false positives, and the inability of Toolformer to interact with it by, for example, reformulating its query if results are not helpful.
Limitations and Future Work
I think the toolformer model could have benefited from demonstrating that making it better at tasks using tools does not make it worse at tasks where it should not use tools — a rewording email task, for example, requires no API calls, but can suffer from worse performance on a model biased to make such calls. This is crucial to prove their “generalization retained” idea.
The toolformer model still cannot use tools in a chain — using the output of one tool as an input to another. This would allow the model to perform more detailed computations.
The model also cannot interact with the tool — especially for tools like search engines, which could potential return hundreds of different results. Something like rewording and browsing would benefit the tool greatly.
The model was also found to be extremely sensitive to the prompt — this could be a factor of the model’s smaller size, or its in-context learning mechanism — any prompt variation tends to bias models.
The process is also very sample-inefficient — processing more than a million documents results only in a few thousand examples of useful calls to the calculator API.
In Summary — I like this paper a lot. It presents a relatively simple idea in a straight forward way, and incredibly, owns up to its flaws and weaknesses. While I imagine budgetary constraints to be a factor, I would have loved to see toolformer scaled up, such that it could make a direct comparison to GPT-3. I’m also not a fan of the need for prompt engineering in fine-tuning and beyond, as mentioned in the paper. However, I am extremely impressed by even a small model’s new-found capabilities, and look forward to reading more work in this domain.