
Using information retrieval for code generation
Models learn to read the docs

Here’s a transparently hidden fact about models — they’re trained once, and deployed forever. That is to say, they don’t keep up with facts as they change. Here’s a classical example with text-davinci-003 on GPT3:

When really:

It is particularly a problem with code generation models — who struggle to keep current with all available APIs. Models cannot inherently generalize to using unseen functions and libraries not in their training data, nor to unknown function signatures of known functions. Something like Copilot could, therefore, never reliably be able to write the code for an API call.
Today, we’re reading “DocPrompting: Generating Code by Retrieving the Docs”.
Introduction and Motivation
Goal: Increase the accuracy of code generation around using APIs and library function calls.
Core Insight: Do it like the humans do — read the documentation!
Solution: Create a natural-language-to-code generation model that leverages code documentation by 1) retrieving the relevant docs 2) generating code using them as one of the inputs.

They theorize that documentation addition eases the mapping between NL intents and code, since the documentation contains both NL descriptions and function signatures.
Development Details
The usage of the retrieved data in the generation process is quite simple — it’s simply added to the generator’s prompt.
So we’ll limit this section to discussing the design of the retrieval system. The goal of this process is to maximize the probability of generating a correct solution, given a documentation set and some NL task description. They use contrastive learning to train a model with recommend the n-best documents for the task.
How does the training work? Sentences from a documentation itself are used as positive learning examples (things to recommend) and sentences from contrasting documentations are used as negative examples (things to not recommend).
This is quite interesting, since contrastive learning is most commonly used in the computer vision domain.
Evaluation
Analyzed on the popular CoNaLa dataset, we see how DocPrompting is an absolute increase in model performance.

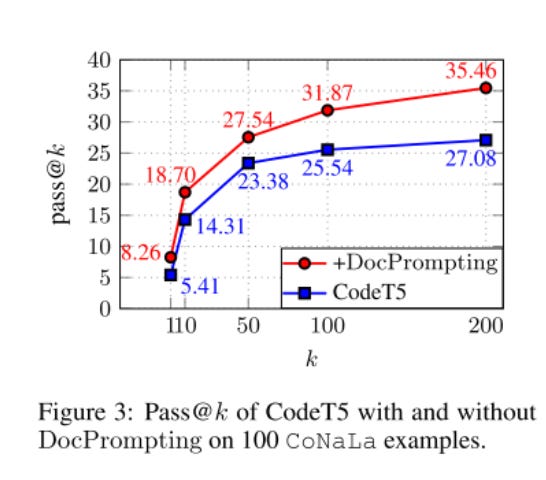
They also compare to example retrieval, a similar approach to docs retrieval:
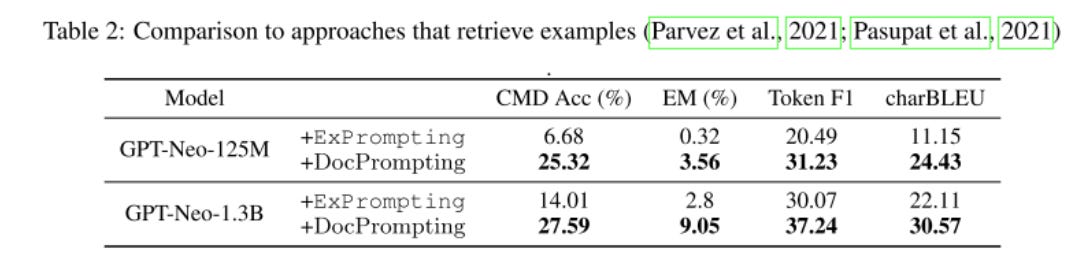
Across the board, it seems like DocPrompting is an improvement over pre-existing techniques in code generation model querying!
Limitations and Future Work
While I commend the unique use of contrastive learning in this case, the problem of NL Task → Documentation translation seems like a much better fit for a shared embedding space. I’d like to see future work investigate the best interface to add retrieval through.
I’m also uncertain as to whether adding the documentation as a whole into the prompt to the model is the best interface for documentation addition. The paper mentions joint training of the retriever and the generator, which could be an excellent next step.
I am a bit disappointed with the evaluation in the paper, since it is based on a dataset they introduce, and CoLaNa (a classical large code generation dataset) and that’s about it. I would’ve liked to see more evidence that DocPrompting generalizes well across domains and languages.
As the paper mentions, their results could perhaps be further improved using more clever encoding of the structured nature of long documents.
In Summary
I want to zoom out a little bit from the domain of code generation to retrieval augmentation in general. If model size remains as big as it is these days, online continuous training of models is not possible. This means that retrieval techniques are especially important for keeping models up to date.
This paper covers some of the general ideas in this domain — training a retrieval model, retrieving the right data, and augmenting the prompt using information. This is going to be a common process in the near future — already seen in examples like the new Bing.
Until next time!