
Meta's new model is small and mighty
LlaMa is stronger than Chinchilla and GPT with only a fraction of the size.

Over the last few years, there’s been a whole lot of research into scaling laws for large language models. First came OpenAI with a paper in 2020 — that paper’s core conclusion was that we must scale the number of parameters in a model to see performance improvements. This is the paper that led to GPT-3 (175B).
Then, Deepmind released a paper in 2022 (this is the famous Chinchilla paper we’ve talked about on TDI previously). This paper said that, on a fixed compute budget, you needed to scale model size and dataset size 1:1 — disagreeing with OpenAI’s conclusions. They trained a 70B model called Chinchilla that outperformed GPT-3 (175B), Gopher (280B) and remains state-of-the-art to this day.

Recently, Meta AI came out with a model, LlaMa, which at 13B outperforms GPT-3, and at 65B performs on level with SOTA models like PaLM and Chinchilla. What’s more — they only trained on publicly available data, which none of the other models can claim.
Today, we’re reading “Open and Efficient Foundation Language Models” to understand how they pulled this off.
Introduction and Motivation
Core Insight: What a lot of ML scaling laws miss is that even more important than the training budget is the inference budget. A smaller model that took longer to train but is cheaper at inference would in the long run be better than a faster-trained larger model.
Solution: Train smaller models with more data, going against Chinchilla scaling laws or emergent ability theories.
Development Details
In total, all model sizes were trained on 1.3T tokens (Chinchilla trained on 1T). Here’s what their data distribution for pre-training looked like:

Here’s training loss plotted against token count, in model training:

The model was trained on 2048 A100 GPU with 80GB of RAM for 21 days.
Efficiency
Am I going to create a whole section on a very small part of the paper interesting to only me and basically no one else? YEP!
Because Meta did something very interesting to make their training more compute-optimal — they didn’t rely on PyTorch. When possible, they replaced the PyTorch autograd with a hand-written backprop function that was compute and memory I/O optimal for their use case. They also overlap the activation and communication between GPUs to minimize communication cost.
This is a small detail, but very common in industry— when training things at scale, you can’t rely on out of the box solutions. Most labs training large models hand-write GPU kernels for such computations.
Evaluation
LlaMa is tested against a lot of benchmarks! Here’s a whole lot of them dumped into one place:
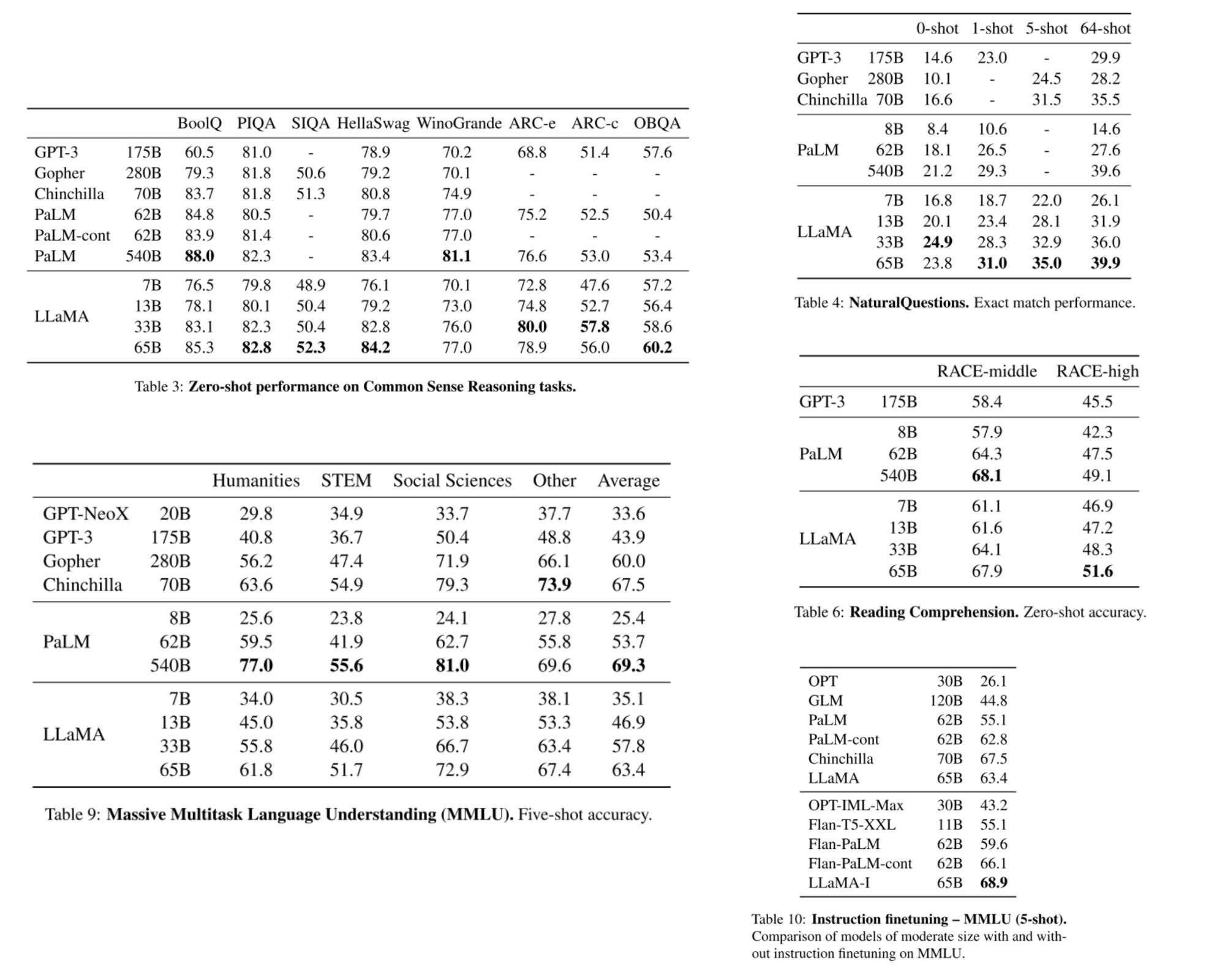
As you can see, LLaMa is pretty competitive with many benchmarks! I want to highlight some interesting observations:
LlaMa does pretty good on code generation, despite only 3.5% of the training set being Github code! This was pretty surprising to me.
LlaMa really doesn’t do too well on MMLU (Massive Multi-lingual Language Understanding) — this is the colloquial “AGI benchmark”. The paper claims this is because their model is not trained on books/papers, which makes for a bulk of the abstract reasoning benchmarks within MMLU.
They also demonstrate that an Instruct model (LlaMa-I) outperforms all models on MMLU. An instruct model is one which is fine-tuned to follow instructions.
Limitations and Future Work
Since fine-tuning the LlaMa model led to such positive results, I’d be interested in seeing further work in fine-tuning these models.
I would have loved to see more depth into the Systems-level and network-level details of training LlaMa, though I do understand that it’s not core to this paper.
The 13B LlaMa model was seeing improvements in performance for all of its 1.3T token training runtime. Crucial future work (I believe you’ll see a paper on this in <1 year) would measure the correlation between dataset size and performance, holding parameter model constant.
In Summary
I haven’t gotten to the punchline of the paper yet — LlaMa is a SOTA model that fits on 1 GPU. You could pull up a Google Colab today and run this model. This is extremely powerful — it implies that very powerful models could be run by anyone who can afford 1 GPU.
The core of this paper is quite pointed at some Meta competitors — it says that models don’t need to be too big, and models don’t need to be trained on proprietary data. Models just need to not be data-starved.
Until next time!